Four Days, from Zero to One: My Descent Into Madness with OKD on Proxmox
![]()
Well, I got it done...
I would say the image perfectly describes how I tend to dive into greenfield tasks. If I am asked to deploy something new (stuff I love doing), my first question is usually, where is the installer? Yes, I will glean the documentation, of course, but I need real context. I want to learn from the inside out.
Service names and what they do, I prefer to know the names and functions through attrition and brute force in real time. Learning the services when they are broken or misbehaving is how you reach true resiliency. I want to see it install and run, then tear it down and do it again, and tighten the documentation. This is essentially what this post is.
With that being said, it was truly loggageddon for a few days, and my eyes were burning.
I’ve deployed Kubernetes in a lab environment before, working through install, cluster, networking, DNS, and ingress to get a functional cluster running. Not for play, but for POC vendor products, etc. While it wasn’t something I used daily, the experience gave me a solid understanding of how the core components fit together. However, it was fleeting, and its been a while.

Honestly, the deployment has an elegance to it. If you get Open Shift into your environment once, additional deploys should basically be: stand up the load balancer, set some DNS and MAC reservations on your network, insert the embedded ISO or PXE, and go for it. Grab lunch, and there is a high probability it will be done when you get back. For me, it was one edge case after another; however, the amount I learned, and refreshed in that time was invaluable.
My goal with this post is to tell the tale. It may help someone else installing this in their Proxmox lab. Without a doubt, it was a difficult install first go. It exposed many edge cases in my home lab setup, some I knew about and some I did not. I will detail them here in case it helps anybody down the road.
It was pretty EPIC. 😄
This post is solely about getting two node worker and master cluster up and running, and maybe adding an additional worker node after its running. I will be following up with many posts about this product, but if it isn't built you cant do anything. I feel the biggest pain point is always getting the thing running dependably, so you can do the "other" thing in a dependable, predictable way.
I will start with a summary of my big issues on this implementation. Hopefully, it will help someone.
Summary of Major Issues Encountered
DNS
I host my own DNS on Pi-hole and Unbound DNS on a LePotato, which I already knew could be a weak point. Normally, my lab uses a more enterprise-style DNS setup, but I implemented ACL-binding to my Pi-hole/Unbound server across all my VLANs. I never went back and fully corrected it for my labs needs.
All port 53 UDP traffic (DNS) across my VLANs is forced to my Unbound server. At the start of this install, I added what I believed were the correct DNS records. Queries were resolving, responses were returned, and everything appeared to be working. All good (nah). I’ll elaborate more on this during the install walkthrough.
The two core DNS issues were:
- The DNS server was not authoritative for the internal domain name I selected
- Rate limiting was occurring in Unbound without my knowledge
100% I would make sure that those two things are rock solid before proceeding. OpenShift pummels your DNS on install, especially in a waiting on fail mode. If its not ready for it, you will be in log hell. I will elaborate with some tests once we get to that stage, if I still have your attention 😉
Quick shout out to my little LePotato DNS. It did not want to do the job, but I made it do the job, and its doing its job. I made so many changes to it pretty fast, I do fear rebooting it. I guess we will find out, but today is not that day. I always have a plan b anyways.
OS Versioning / BIOS
Desperation Alley
- Once I had the 4.20 installer, I was trying to figure out what version CoreOS I should be using. I could not tell you what led me to FCOS 42, and it might have worked, but I had yet to expose many other issues.
- I was getting crazy behavior. Some installs would work to a certain point and then stop. And then I would see some of the manifests created, and then they would stop. I saw errors that indicated maybe it was a BIOS issue, that I should be using EFI, and went fully down that path, which almost was the end of me. At the time, I was typing the kernel args for the ignition in the console, which was just brutal.
I'll talk more about that when we get to it further down the road. The main thing is the installer is the ONLY source of truth. I would not get fancy with it. I will give you the commands when we get to the install portion of this blog.
If I had run across that tidbit above, the title of this article would have been Three Days, Zero to One. Eh, anyway, I digress...
NTP
The Mind Killer
- I was pretty sure this was set correctly, but make sure your Proxmox hosts are syncing time, or its a whole circular abyss.
Server Overheating
Snatching defeat from the jaws of victory
- This one is kind of self explaintory and was funny because it was litteraly right at the moment of victory
- It died 3 times had to reboot, I threw some fans on it and it was resolved still tragically funny
- To be fair it was on HP EliteDesk 705 G4 Ebay specials that I upgraded to 64GB Memory (before RAMpocalypse).

The chassis is a bit tight 🙂 powerful machines for the money though, it was never at any point slow.
OK Install Time:
This is the basic diagram of what will will be doing. We will be doing a bare metal type install, and close to prod type of deploy. I would expect in an actual bare metal deploy all of this stuff would work. Another note here, we will not be getting to VM creation until much later in this document. The VM's are the last consideration.

Non negotiable: lock in your DNS names, changing these after the install = Very Bad, as in just do it over.
Choose your load balancer. I have deployed both ngnix and HAProxy, and there is no appreciable difference to OpenShift. Having installed and configured both, nginx I had to mess with a bit more. It wasn't a big deal, but at the time everything was. Just choose what you are comfortable with.
HAProxy is a simple install on any RH Adjecent OS and here is my config. As well as some follow up validation
#Install
dnf install -y haproxy
systemctl enable haproxy
systemctl start haproxy
#Start
systemctl enable haproxy
systemctl start haproxy
#Add FW
firewall-cmd --permanent --add-port=6443/tcp
firewall-cmd --permanent --add-port=22623/tcp
firewall-cmd --permanent --add-service=http
firewall-cmd --permanent --add-service=https
firewall-cmd --reload
firewall-cmd --list-all
#Setup
mv /etc/haproxy/haproxy.cfg /etc/haproxy/haproxy.cfg.orig
nano /etc/haproxy/haproxy.cfg
#Test
ss -lntp | egrep '(:6443|:22623|:80|:443)'#nano /etc/haproxy/haproxy.cfg
global
log /dev/log local0
log /dev/log local1 notice
daemon
maxconn 2000
defaults
log global
mode tcp
option tcplog
timeout connect 10s
timeout client 1m
timeout server 1m
# =========================
# API SERVER (6443) !!!This is Pointed at Boostrap early stages, then moved to master!!!
# =========================
frontend openshift-api
bind *:6443
default_backend openshift-api-master
backend openshift-api-master
balance roundrobin
server master 172.26.7.53:6443 check
# =========================
# MACHINE CONFIG SERVER (22623) !!!This is Pointed at Boostrap early stages, then moved to master!!!
# =========================
frontend machine-config
bind *:22623
default_backend machine-config-master
backend machine-config-master
balance roundrobin
server master 172.26.7.53:22623 check
# =========================
# INGRESS HTTP (80)
# =========================
frontend openshift-apps-http
bind *:80
default_backend openshift-apps-http
backend openshift-apps-http
balance roundrobin
server worker 172.26.7.52:80 check
# =========================
# INGRESS HTTPS (443) – TCP PASSTHROUGH
# =========================
frontend openshift-apps-https
bind *:443
mode tcp
default_backend openshift-apps-https
backend openshift-apps-https
mode tcp
balance source
server worker 172.26.7.52:443 checkVerify and restart
#Verify and restart
haproxy -c -f /etc/haproxy/haproxy.cfg
systemctl reload haproxy
ss -lntp | egrep '(:6443|:22623|:80|:443)'These endpoints will be the ingress for the OpenShift cluster they will point to the HAProxy IP. Just note for now we will be changing two of these backend IP's to the master IP at a set point in the install.
api.okd.vv-int.io 172.26.7.50
api-int.okd.vv-int.io 172.26.7.50
*.apps.okd.vv-int.io 172.26.7.50VM DNS
vv-bootstrap-okd.vv-int.io A 172.26.7.53 # disposed of after the install
vv-master-01-okd.vv-int.io A 172.26.7.51 # It's good to be king
vv-worker-01-okd.vv-int.io A 172.26.7.52 # backbone
Have these DNS names bound and tested before anything.
I will say it one more time: TEST YOUR DNS!!!
In the end, after a successful deploy, things will look like this from an OpenShift perspective.
| Purpose | Derived FQDN |
|---|---|
| External API | api.okd.vv-int.io |
| Internal API | api-int.okd.vv-int.io |
| Apps wildcard | *.apps.okd.vv-int.io |
| OAuth | oauth-openshift.apps.okd.vv-int.io |
| Console | console-openshift-console.apps.okd.vv-int.io |
Here are all the DNS commands I used to validate resolution.
nslookup test.apps.okd.vv-int.io # tests wildcard
dig test.apps.okd.vv-int.io # get a real look
dig api.okd.vv-int.io +short # validate API endpoints
dig api-int.okd.vv-int.io +short # validate API endpoints
dig oauth-openshift.apps.okd.vv-int.io +short # probably overkill but also not
dig console-openshift-console.apps.okd.vv-int.io +short # probably overkill but also not
dig does-not-exist.apps.okd.vv-int.io +short # testing fullIf everything is good to that point, I would just check that your DNS server is up to traffic load.
for i in {1..50}; do dig test.apps.okd2.vv-int.io +short; done # burst test
for i in {1..200}; do dig test.apps.okd2.vv-int.io +short; sleep 0.1; done # sustainedAny timeouts could potentially destroy all that you are attempting to build, and that would be sad.
The VM's
Assuming you are good here, we will talk about the VM's, only from a DNS/DHCP perspective. These are the names I chose for each in my environment.
vv-bootstrap-okd.vv-int.io A 172.26.7.53 # disposed of after the install
vv-master-01-okd.vv-int.io A 172.26.7.51 # It's good to be king
vv-worker-01-okd.vv-int.io A 172.26.7.52 # backboneApparently, these do not need, according to some documentation and random AI results, to actually be in DNS from the perspective of OpenShift “doing its thing.” However, if you ever want to log into them by name resolution… yeah, nah, put them in DNS.
OKD wants LiveISO or PXE install of CoreOS, I did not feel like setting up dependable PXE (maybe later), this is the path I chose:
- Kernel arguments one of two ways: embedded, or type manually into a console 🤮🤮🤮 <- I vomit because I felt the pain.
- DHCP MAC reservations.
I chose DHCP/MAC reservations. I applied the reservations to my router, and set the DNS.
So now we are here:
vv-bootstrap-okd.vv-int.io A 172.26.7.53 BC:24:11:EF:E5:39
vv-master-01-okd.vv-int.io A 172.26.7.51 BC:24:11:93:A4:65
vv-worker-01-okd.vv-int.io A 172.26.7.52 BC:24:11:25:29:A6This is the most flexible to me. I set the DNS, I bind the MAC to that IP, and nothing is embedded to the ISO. It allows me to use the embedded kernel argument ISO's for multiple installs. VM gets its hostname from DNS. We will be getting to those shortly.
Downloading the installer
OK, now choose a Linux VM on your network that can talk to all this stuff, and make yourself an install directory. I used the ngnix / HAProxy, but it could be any VM.
Make yourself a directory.
mkdir -p /root/okd/installer # whatever works for you
cd /root/okd/installer # you know the drillNow lets get the things: install, client, verify the CoreOS install download location, and clean up a little.
# Installer
curl -L \
https://github.com/okd-project/okd/releases/download/4.20.0-okd-scos.2/openshift-install-linux-4.20.0-okd-scos.2.tar.gz \
-o openshift-install-linux-4.20.0-okd-scos.2.tar.gz
tar -xvf openshift-install-linux-4.20.0-okd-scos.2.tar.gz
chmod +x openshift-install
# Client OC/kubectl
curl -L https://github.com/okd-project/okd/releases/download/4.20.0-okd-scos.2/openshift-client-linux-4.20.0-okd-scos.2.tar.gz \
-o openshift-client-linux-4.20.0-okd-scos.2.tar.gz
tar -xvf openshift-client-linux-4.20.0-okd-scos.2.tar.gz
chmod +x oc kubectl
# Lets see what we have
ls -la
# get the version verify
./openshift-install version
# Get exact CoreOS version download link
./openshift-install coreos print-stream-json | \
jq -r '.architectures.x86_64.artifacts.metal.formats.iso.disk.location'
# Clean it up
mv openshift-client-linux-4.20.0-okd-scos.2.tar.gz openshift-install-linux-4.20.0-okd-scos.2.tar.gz ../
What you should be seeing
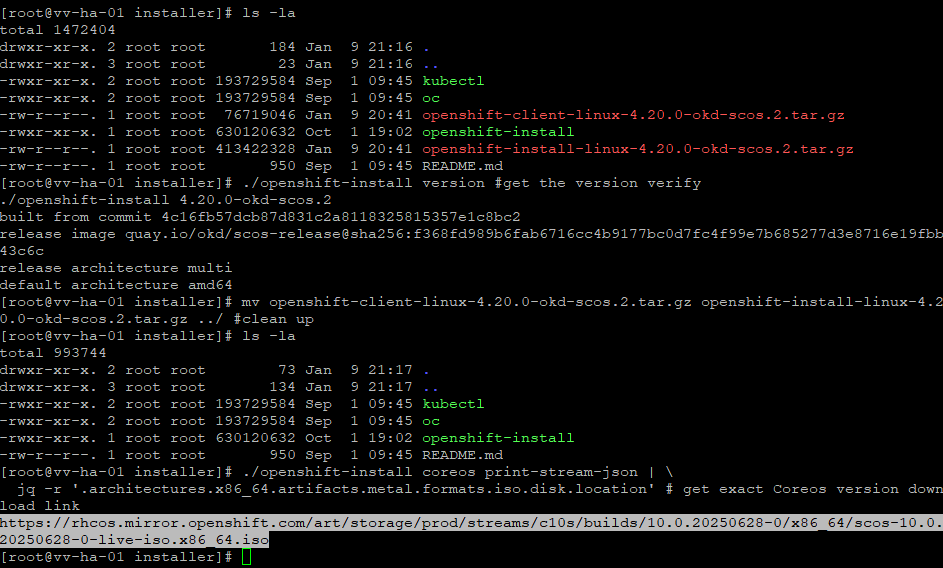
OK, as derived from the installer, the ISO link is
curl -O https://rhcos.mirror.openshift.com/art/storage/prod/streams/c10s/builds/10.0.20250628-0/x86_64/scos-10.0.20250628-0-live-iso.x86_64.iso
# go get that tasty isoWhat we should have now

OK, now we have everything needed to install.
This is where I pause to talk about the install process before we get into the VM/ISO prep.
What we will be doing next, in this order:
- Get a pull secret and extract the JSON in proper format for install-config.yaml
- Create the install-config.yaml config file with basic install variables as I know them today
- Create the ignition configs from that file, these are what the CoreOS builds fetch
- Talk about approaches for applying kernel args
- Then we will prep the VM's in Proxmox
Note: when you just run the installer without passing a YAML file, it will just present a ton of different provider options. I found none of them dependable for my install, and you can just create your own YAML and go.
I am showing this image as an example of what not to do
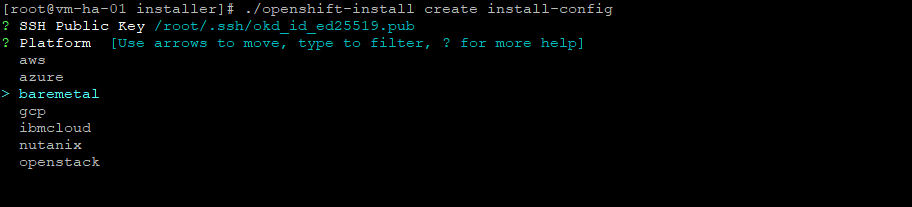
The following is necessary to build the install-config.yaml, which is core to this install.
Get the Pull Secret from quay.io
On my first successful install of OKD, I used a pull secret from the Red Hat Network. I noticed that it also had quay creds in there. When I finally got things running, I saw a ton of red and no hats. It turns out it was because OKD was trying to pull from the Red Hat registry, not fatal, and you just remove. I want to do this install as clean as possible, so I am scoping to OKD.
OKD uses Quay as its upstream image registry. Authentication is optional but recommended to avoid image pull rate limits during installation.
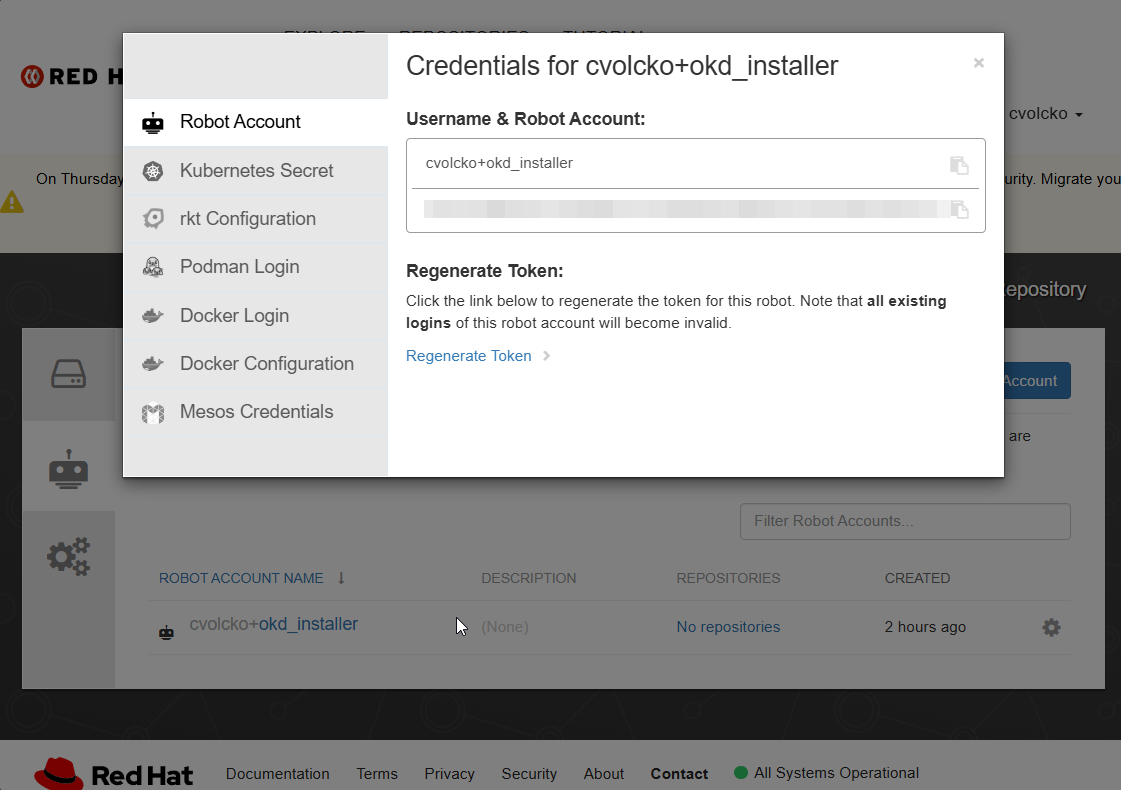
Use Quay robot account:
- Go to: https://quay.io
- Create an account (or log in) (this appears to bounce you to Red Hat for Auth, then to Quay)
- Create a robot account
- Example: myuser+okdrobot
- Grant it read access (public repos are fine, but auth avoids rate limits)
- Get credentials
- You’ll end up with:
- Username: myuser+okdrobot
- Password:
About how it should look:
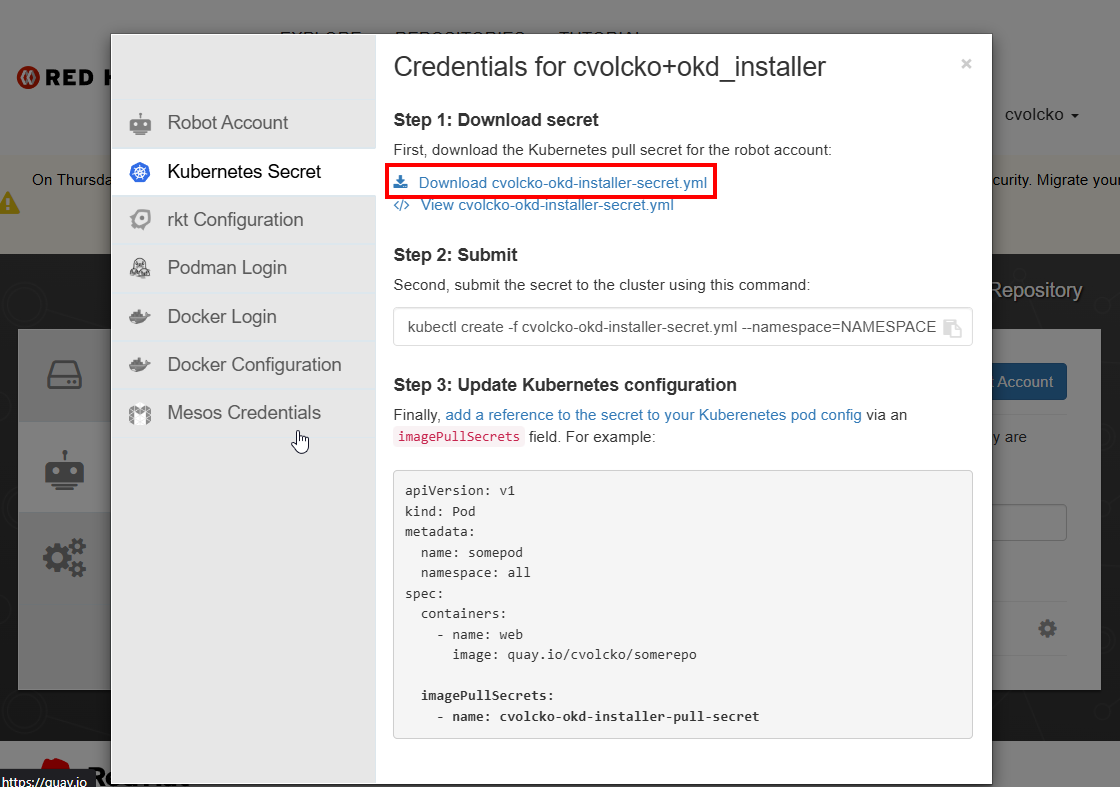
Download it to your installer machine in the install directory, then run the following on it. It will pull it in a format that works for copying and pasting into the install-config.yaml. I was beating my head against this one for a while until I got a format that the installer would take. All these instructions would be the same if you were doing straight OpenShift, but you would be getting the pull secret direct from the Red Hat site at that point. I noticed that Quay gives you a .yaml, and RHN gave me a .txt file. I will include commands for both versions.
OKD
# give me the format now
grep '\.dockerconfigjson:' cvolcko-okd-installer-secret.yml \
| awk '{print $2}' \
| base64 -dThis will give you valid JSON format for your install-config.yaml. Copy and paste that somewhere, getting ready to create the install-config.yaml.

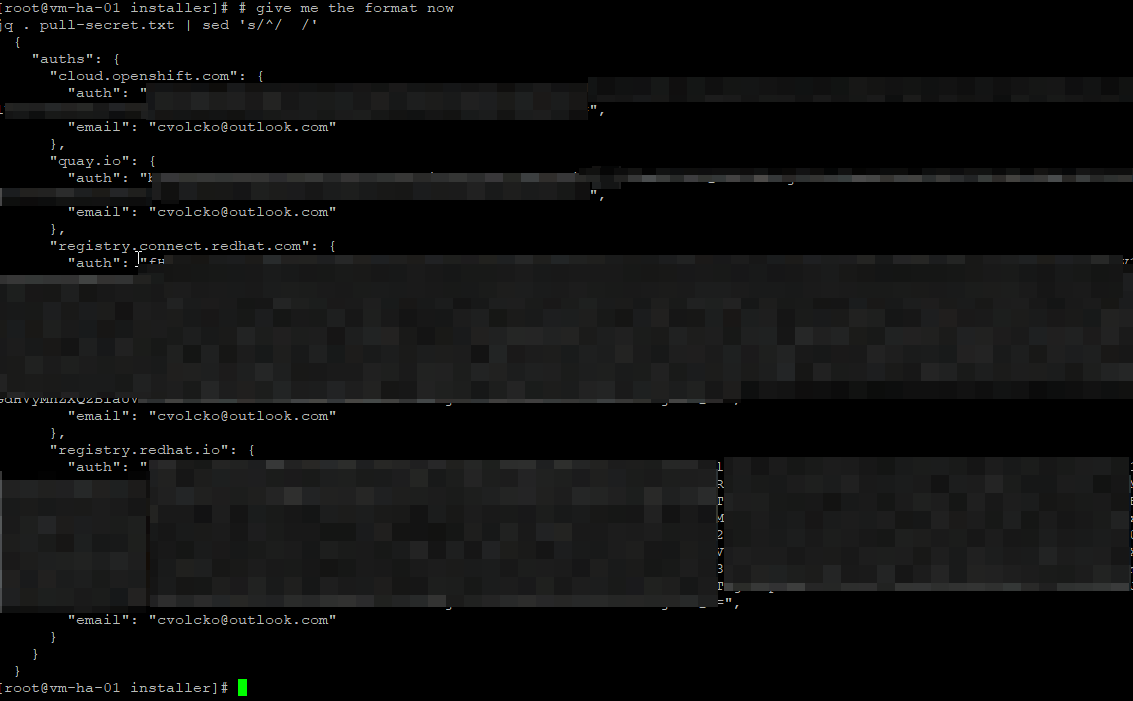
RHN
# give me the format now
jq . pull-secret.txt | sed 's/^/ /'
SSH Key
# give me my server SSH key please
ssh-keygen -t ed25519 -f ~/.ssh/okd_id_ed25519
cat ~/.ssh/okd_id_ed25519.pub
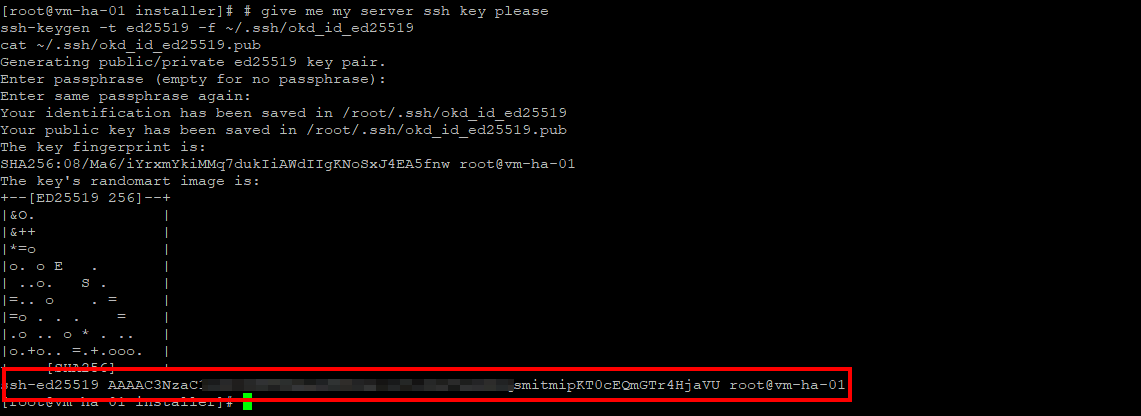
Copy the whole line and save it, nothing fancy, the root@vv-ha-01 is a description field; its not necessary.
The SSH key provided in install-config.yaml allows the installer and the administrator to securely access cluster nodes for debugging during and after installation. It is not used by Kubernetes itself and is only injected for human access.
Time to create the installer config
I know we have not even got to the VM's yet, and its deliberate. If everything is rock solid and done in this order, it will be obvious and sane. Honestly, the VM's are the last consideration on the list. Now lets get to creating the legendary installer-config.yaml!!!
Note: once you create ignition files, the installer will delete your install-config.yaml. It was another stimulating find, but security conscious. Work from a backup directory and copy over for the install.
Also: ignition, manifests, and install metadata are MAX good for 24 hours (I cannot find an exact number). Hypothetically, say you have your templates all nice and snapshotted and you are cruising through multiple install attempts just to get a repeatable MOP. It may work for four attempts with the same ignition files, but at some point you will start burning time figuring out why the SSL errors exist.🙃
If you decide to do another deploy off your templates the next day, just delete all the files created by the installer and start over.
# From installer dir delete all files created from the installer
rm -rf auth tls metadata.json bootstrap.ign master.ign worker.ign manifests openshift *.ign *.jsonAsk me how I know ?
First thing I will show is just the commented version of install-config.yaml so we can understand whats happening here. This file is purely for documenting its fairly self-explanitory, I have a saved version of this I reference.
##### EXAMPLE ONLY ######
apiVersion: v1
# Installer API version (always v1 for OKD / OpenShift 4.x)
baseDomain: vv-int.io
# Existing DNS domain.
# The installer builds cluster names as:
# <cluster-name>.<baseDomain>
# Example:
# api.okd.vv-int.io
# *.apps.okd.vv-int.io
metadata:
name: okd
# Cluster name (subdomain under baseDomain, this to me is the magic because thats the only thing that really needs to flip with additional installs)
compute:
- name: worker
replicas: 1
# Workers run the router, web console, and workloads
platform: {}
controlPlane:
name: master
replicas: 1
# Control-plane nodes run the API and etcd
platform: {}
platform:
none: {}
# Bare metal / UPI install (no cloud provisioning)
networking:
networkType: OVNKubernetes
clusterNetwork:
- cidr: 10.128.0.0/14
hostPrefix: 23
serviceNetwork:
- 172.30.0.0/16
pullSecret: |
{
"auths": {
"quay.io": {
"auth": "REDACTED",
"email": ""
}
}
}
# Registry auth for pulling OKD images from quay.io
sshKey: |
ssh-ed25519 AAAAC3... root@vm-ha-01
# SSH access as 'core' for debuggingOk so now a clean version of installer yaml for my enviornment, adjust for yours.
apiVersion: v1
baseDomain: vv-int.io
metadata:
name: okd
compute:
- name: worker
replicas: 1
platform: {}
controlPlane:
name: master
replicas: 1
platform: {}
platform:
none: {}
networking:
networkType: OVNKubernetes
clusterNetwork:
- cidr: 10.128.0.0/14
hostPrefix: 23
serviceNetwork:
- 172.30.0.0/16
pullSecret: |
{
"auths": {
"quay.io": {
"auth": "YOURPULLSECRET",
"email": ""
}
}
}
sshKey: |
ssh-ed25519 YOURSSHKEYHERE root@vm-name-01Now this is what your dir should look like.
Ok now we will be creating the manifests this is also a validation test, if your YAML is broke this step should expose this. Manifests are the installer-generated Kubernetes resources used during the bootstrap phase
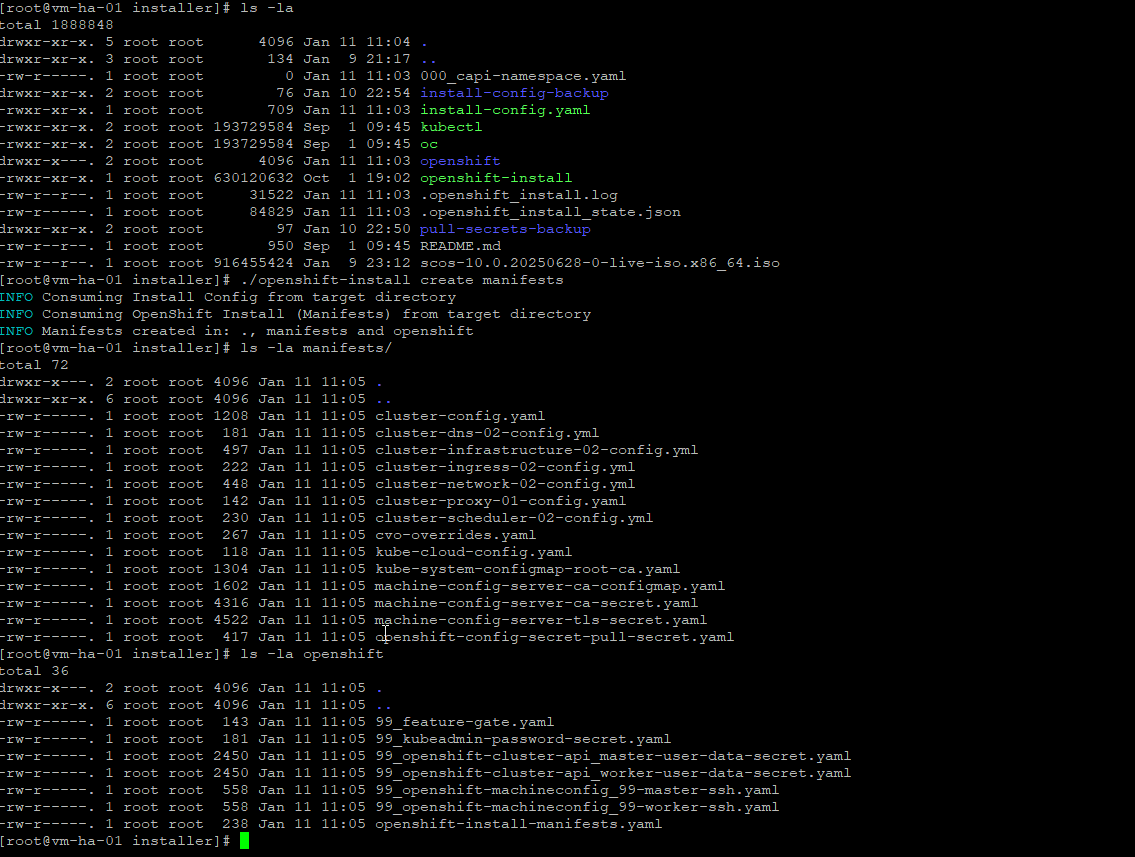
Lets create some manifests
./openshift-install create manifestsThis is what you should be seeing now, if you get an error at this phase its good beause most likely its a simple formatting error. The installer creates two directories manifests/ and openshift/
Ok we got those tasty manifests, this lets create those ignitions, there will be 3, bootstrap,master,and worker 🚀🚀🚀 Just one more warning have your install-config.yaml backed up because this step consumes the file and deletes it.
./openshift-install create ignition-configsYou will see your ignition files created and auth/ directory added. The auth/ directory holds the initial admin credentials required to access and manage the cluster during and immediately after installation.
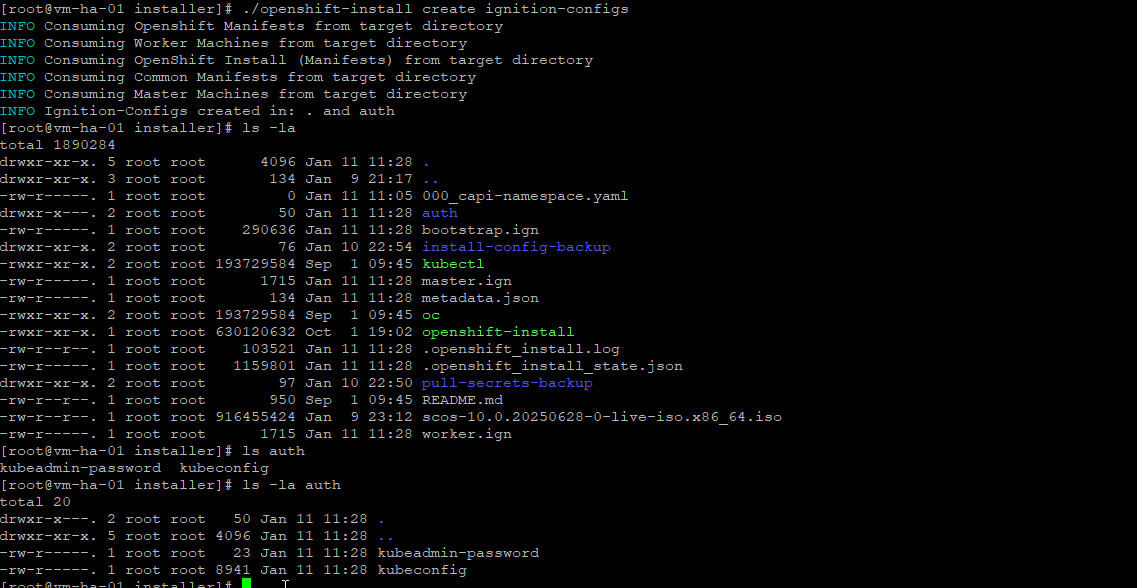
Ok so this is were we will talk about next steps, we are close to VM config.
- We now have bootstrap.ign, master.ign, worker.ign we will be serving them soon, but not yet.
- In my enveronment I just used a Python server for hosting them so I dont fire that up until ignition time, but its a good time to validate
Make sure you are in the installer directory (where the ignition files live)
These files we will serve on a web server ( in my case a temporary python server directly in the installer directory)
# FW Rules
firewall-cmd --add-port=8080/tcp
firewall-cmd --add-port=8080/tcp --permanent
firewall-cmd --reload# run the server
python3 -m http.server 8080

Test these from a VM that is not the installer machine, for extra sanity
curl -I http://172.26.7.50:8080/bootstrap.ign
curl -I http://172.26.7.50:8080/master.ign
curl -I http://172.26.7.50:8080/worker.ign
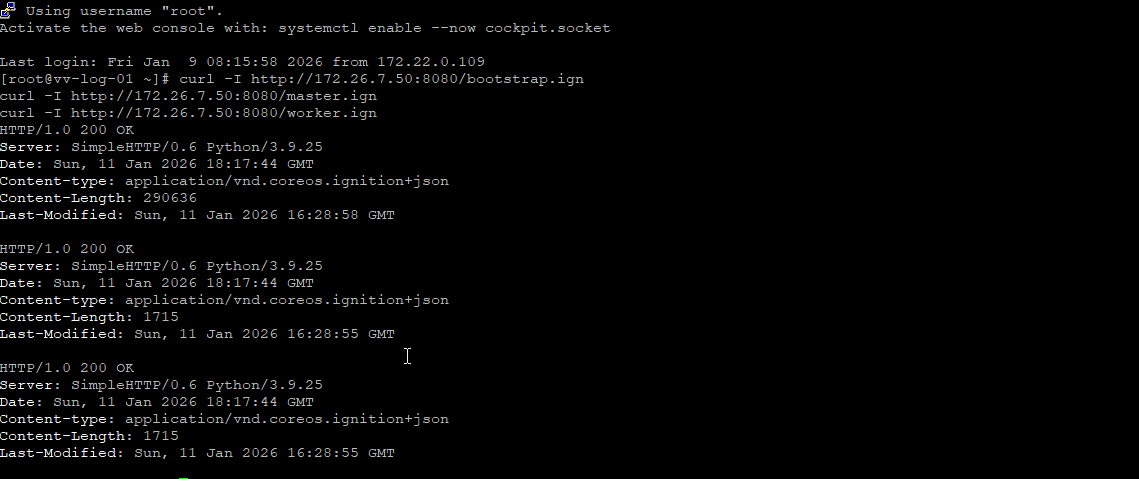
Ok that looks good 👍
About the kernel arguments
Kernel arguments provide the live installer with the target disk and ignition URL so the node can self-install and configure on first boot. There are two approaches to this. Well there are 3 options if you include PXE, but thats is for another day.
For this run the options are.
- Type them manually at boot in the Proxmox Console
- Embed them in the iso using CoreOS installer
After suffering through typing these lines into a console repeatedly, my only suggestion is to do it embedded. I will walk you through it next. Get one character wrong and you might as well rebuild the VM. Snapshotting and templating usually spiral into a net loss of time.
About embedding the kernel args in the iso itself
- This just requires installing coreos-installer
- We will be installing coreos-installer creating a new directory and customizing the ISO's there
- We will end up with 3 different ISO that we will be attaching to the individual templates
I will be installing coreos-installer on my AlmaLinux 9 HAProxy/installer VM
dnf install -y epel-release
dnf install -y coreos-installerRemember that ISO we downloaded way back when? We are now going to embed the kernel args using coreos-installer. Make a new directory in the installer directory, move the ISO into it, and let’s work there.
# make a new dir in the istaller dir and move the iso into it
mkdir coreos
mv ./scos-10.0.20250628-0-live-iso.x86_64.iso coreos/
cd coreos
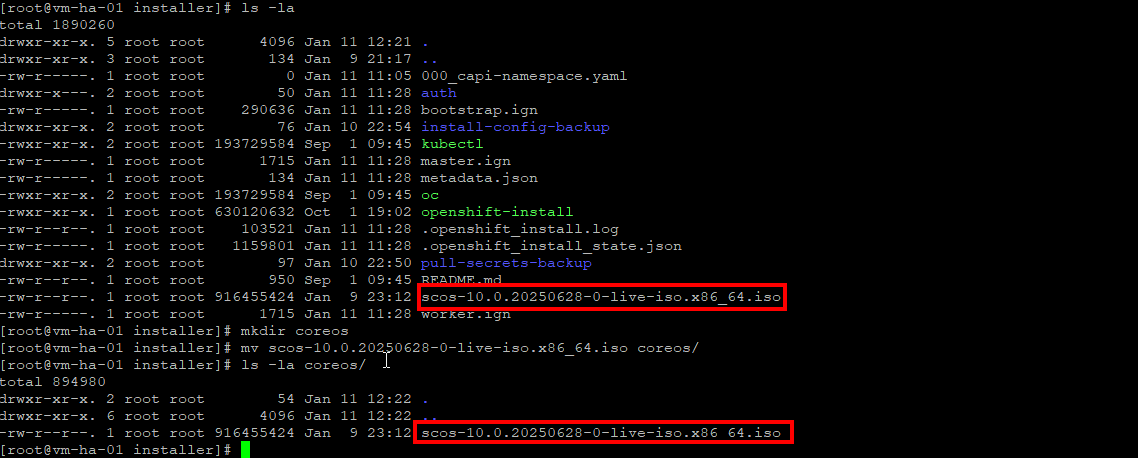
So now we will embed the kernel arguments and will end up with three ISO that we will attach to Proxmox VM's properly configured and we will call them base templates I don't have them flagged as templates I just clone them per install attempt. Below is the config that worked for me, the VM's get hostnames though the MAC DHCP reservations and DNS.Adjust the ignition file urls to your enviornment.
# bootstrap
coreos-installer iso customize \
--live-karg-append coreos.inst.install_dev=/dev/sda \
--live-karg-append coreos.inst.ignition_url=http://172.26.7.50:8080/bootstrap.ign \
scos-10.0.20250628-0-live-iso.x86_64.iso \
-o scos-bootstrap-okd.iso
# master
coreos-installer iso customize \
--live-karg-append coreos.inst.install_dev=/dev/sda \
--live-karg-append coreos.inst.ignition_url=http://172.26.7.50:8080/master.ign \
scos-10.0.20250628-0-live-iso.x86_64.iso \
-o scos-master-okd.iso
# worker
coreos-installer iso customize \
--live-karg-append coreos.inst.install_dev=/dev/sda \
--live-karg-append coreos.inst.ignition_url=http://172.26.7.50:8080/worker.ign \
scos-10.0.20250628-0-live-iso.x86_64.iso \
-o scos-worker-okd.isoSo once this is done you will have 3 ISO in the directory scos-bootstrap-okd.iso, scos-master-okd.iso, scos-worker-okd.iso
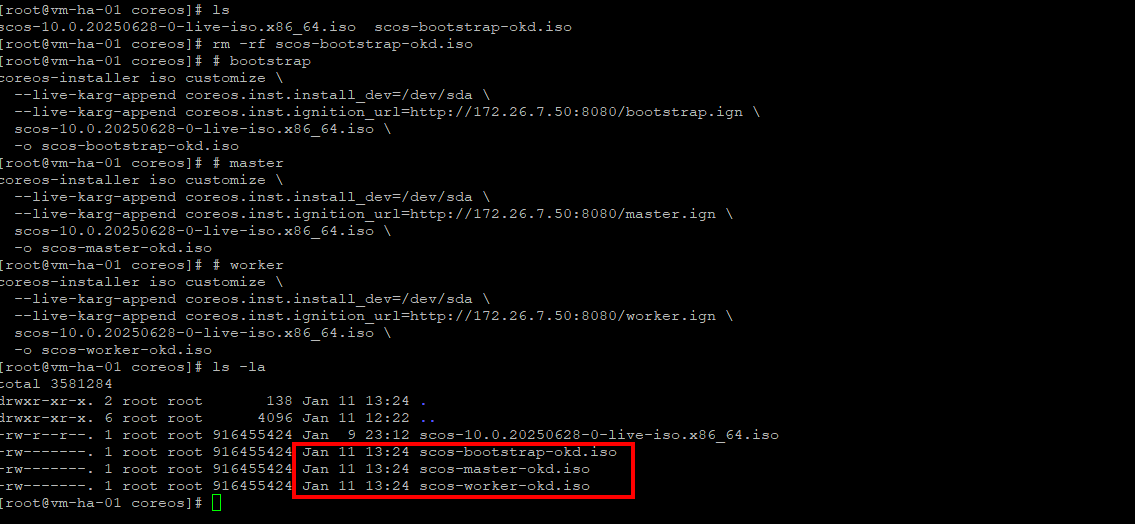
Upload them to your Proxmox sever and finally after years of prep we can get to VM creation
VM creation
It goes without saying but I will say it. You must make sure Virtualization is enabled in your hypervisor
lscpu | grep Virtualization
root@pve01:~# lscpu | grep Virtualization
Virtualization: VT-x
root@pve01:~# lscpu | grep -i vmx
Flags: vmxIf you don't see output like that go get it fixed, probably a BIOS issue
Moving on:
You will see below I have 3 pre-seeded VM templates.
My process:
- Attach appropriate ISO per VM name
- Clone VM using actual DNS name as vmname (shortname)
- Once VM is cloned apply the proper MAC to each of the NIC
- Snapshot them in pristine powered off state, you will thank me later
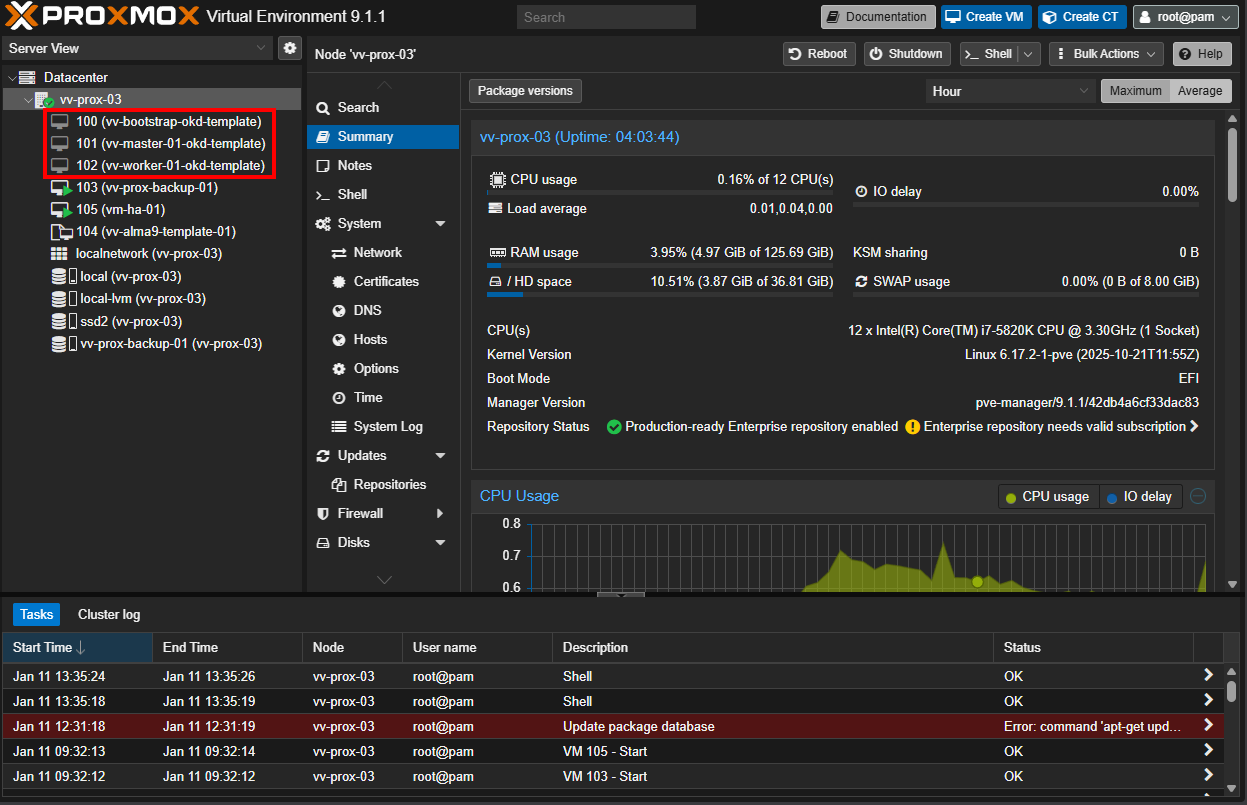
Remember these ?
######################################### The Sauce
vv-bootstrap-okd.vv-int.io A 172.26.7.53 BC:24:11:EF:E5:39
vv-master-01-okd.vv-int.io A 172.26.7.51 BC:24:11:93:A4:65
vv-worker-01-okd.vv-int.io A 172.26.7.52 BC:24:11:25:29:A6So what I am going to do is show you the VM Config that matters. The Images below should show you all the important VM config
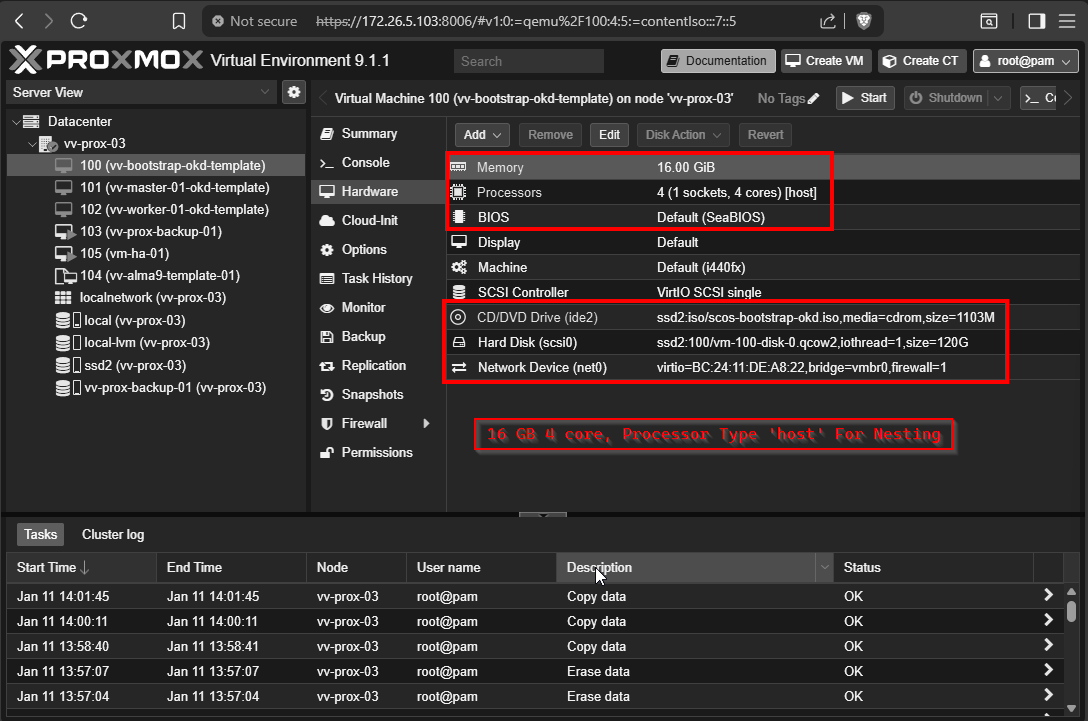
VM Config should be as follows:
- Memory 16 GB Min (all templates)
- Disk 120 GB (all templates)
- CPU 1/4 (1 socket 4 cores) TYPE HOST
- Proper embeded ISO for the machine you are about to deploy
- Proper boot order ##Extremely important DISK --> Then ISO
- Proper MAC added for the VM you are deploying
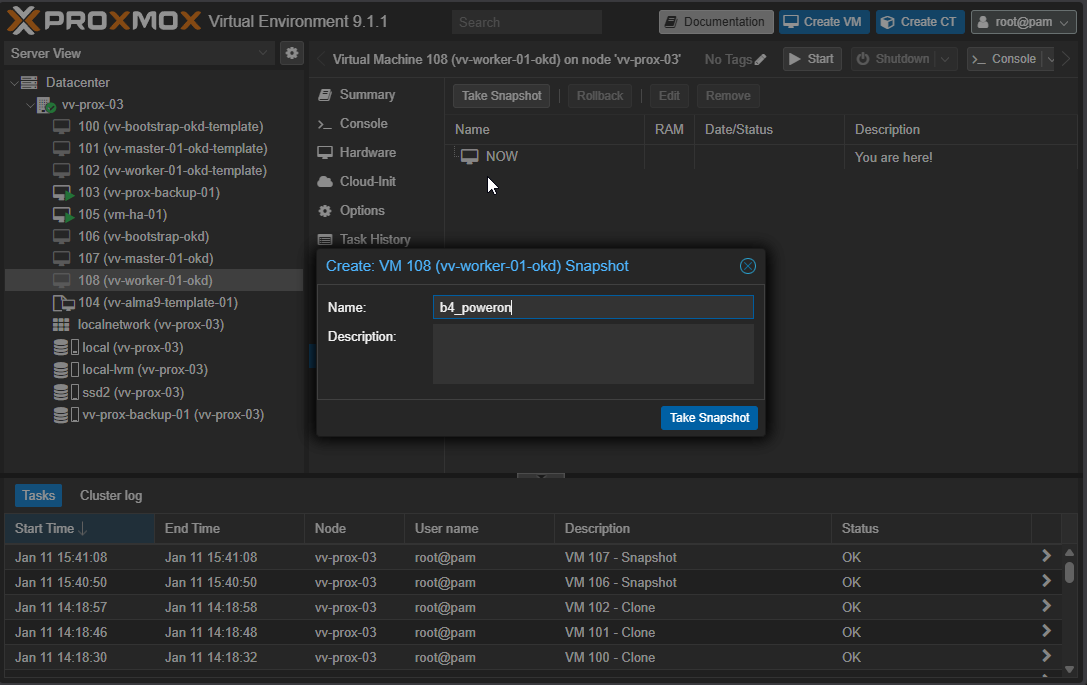
I clone from the template VM's and Snapshot them in a powered off state
VM Config Template Prep
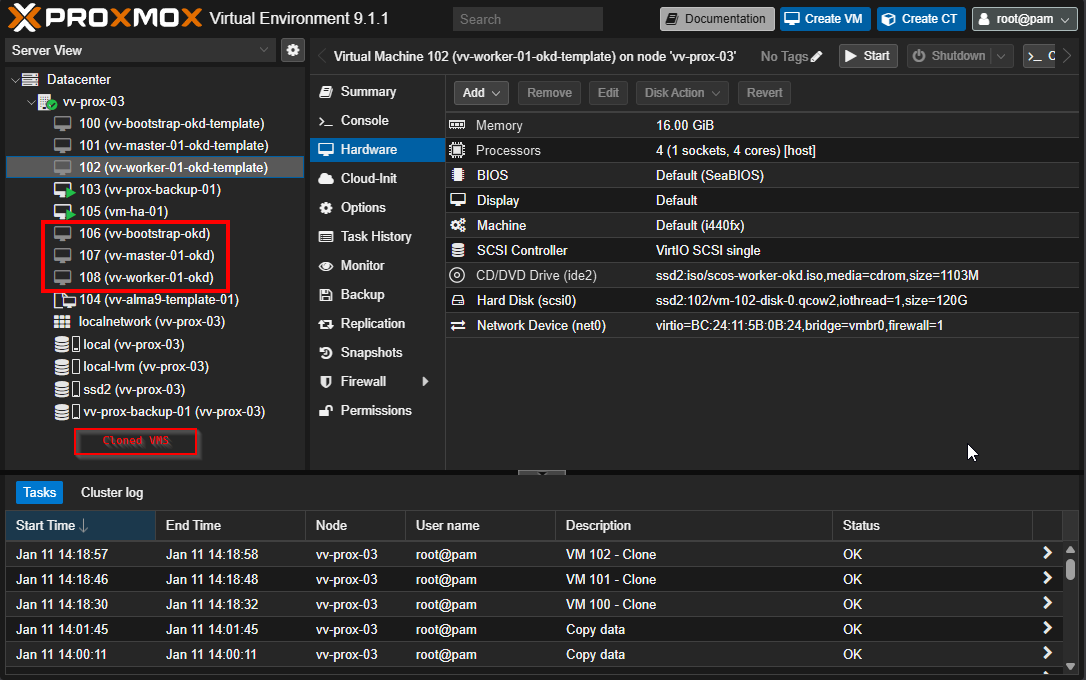
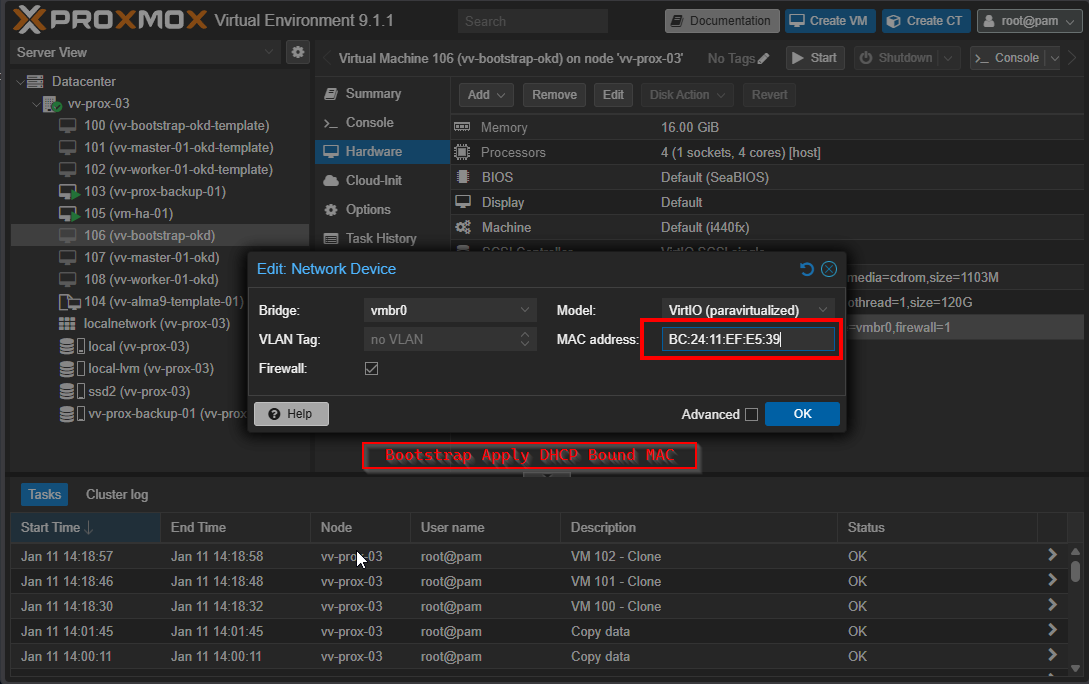
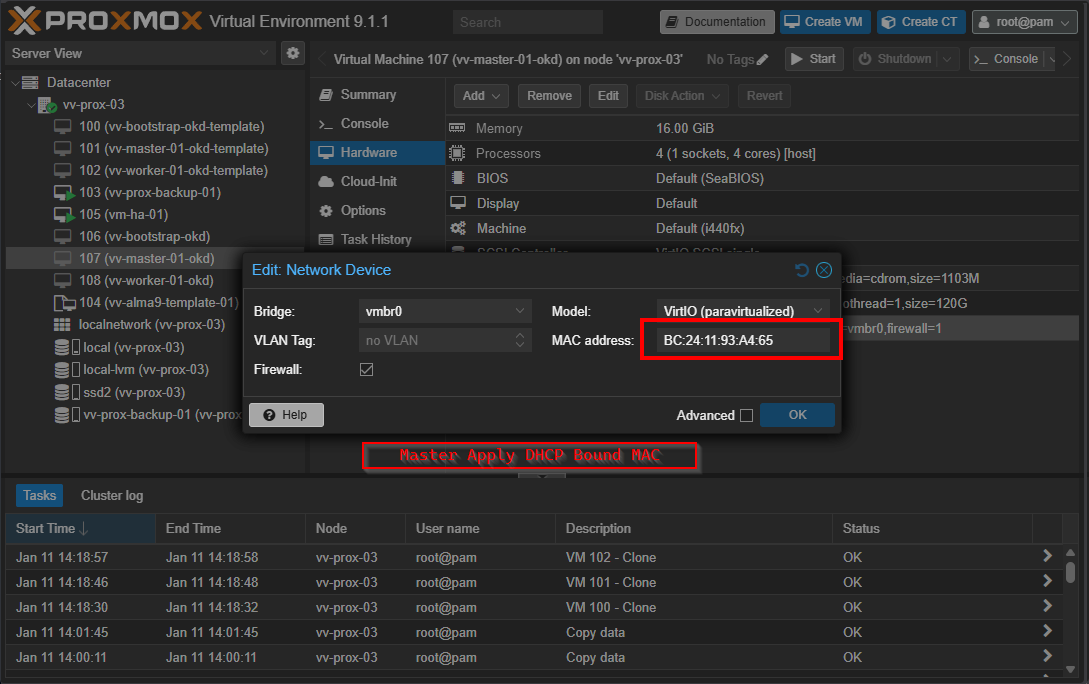
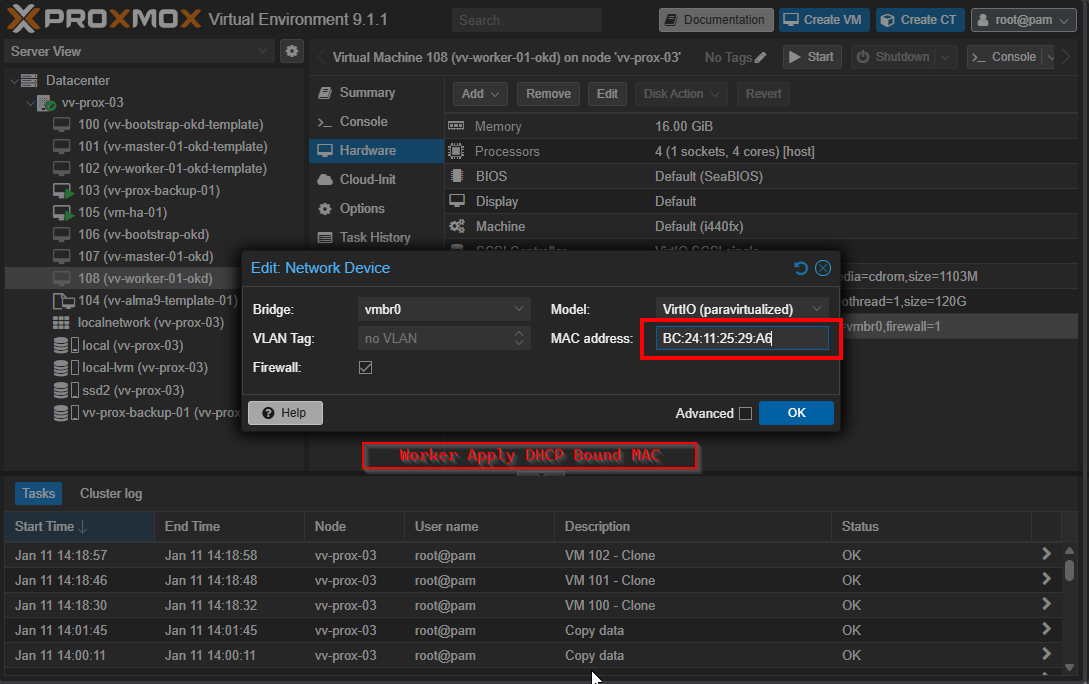
ONE MORE TIME: Make sure the MAC address on the NICs are proper to what you decided If DHCP and DNS are working correctly, this is how the VM gets its hostname. If the VM boots incorrect MAC, even after ignition runs, the console will still show localhost. Forget DNS for a second, if the MAC's are not right the VM's won't get the right IP's that correspond to the HAProxy config. So yeah do the work. I would test on a VM ahead of time.
Proper boot order Extremely important DISK --> Then ISO **
At this point:
- We have cloned the VM's
- We have verified that they all have the proper ISO
- We have verified that they all the the proper MAC assigned at the NIC
I snapshot these VM's in a never booted and powered off state as it allows for easy recovery.
One last check before we power these on:
- Make sure you have your python server up and running or the VM's will get no ignitions
- Lets do one more sanity check of the network
Python server in install dir (ignition file location):
python3 -m http.server 8080Test DNS
nslookup test.apps.okd.vv-int.io # tests wildcard
dig test.apps.okd.vv-int.io # get a real look
dig api.okd.vv-int.io +short # validate API endpoints
dig api-int.okd.vv-int.io +short # validate API endpoints
dig oauth-openshift.apps.okd.vv-int.io +short # probably overkill but also not
dig console-openshift-console.apps.okd.vv-int.io +short # probably overkill but also not
dig does-not-exist.apps.okd.vv-int.io +short # testing fullPush the DNS server
for i in {1..50}; do dig test.apps.okd2.vv-int.io +short; done # burst test
for i in {1..200}; do dig test.apps.okd2.vv-int.io +short; sleep 0.1; done # sustainedTest the LB
nc -vz api.okd.vv-int.io 6443
nc -vz api.okd.vv-int.io 22623Verify you are serving igntion files
curl -I http://172.26.7.50:8080/bootstrap.ign
curl -I http://172.26.7.50:8080/master.ign
curl -I http://172.26.7.50:8080/worker.ignThis is my typical boot order
- Fire up bootstrap and wait for signals that its ready for me to boot master see below
- Once I have found the signal on bootstrap, I boot master and I wait for the signal to flip the HAProxy backend to point to --> master this one was a mystery at first.
- Once that is done wait for signal to boot the worker
- Fix master taint and UI behavior
Before we power on
Talking about the installer for a moment, it is not bad in the sense that if you do all your testing, everything should just work. However, a few things are definitely blockers. Because of all the “things” going on, and the differences in timing of each of these services due to hardware differences, speed, etc., it is difficult to find a single source of truth that it is doing what it should be doing. Here are the issues that hit me on every single deploy. I would also test your MAC/DHCP binding with another VM just to make sure you set everything up correctly.
These are the blockers I hit every single time
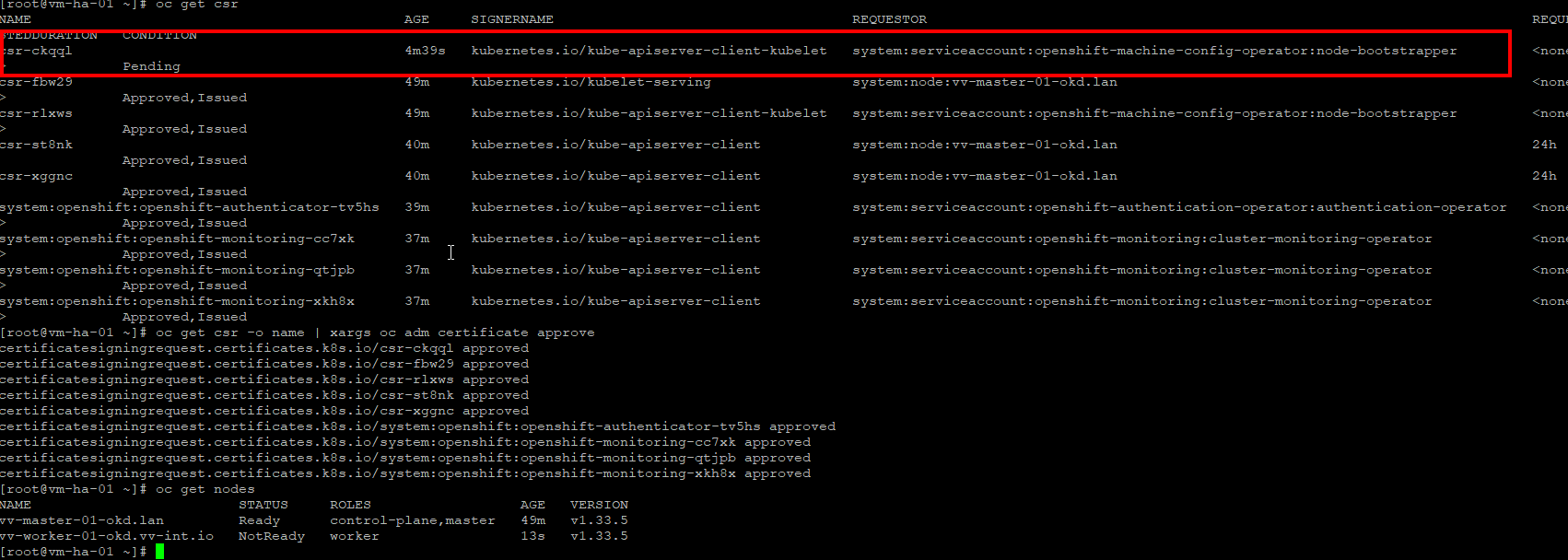
- Once worker booted I had to manually approve the CSR's (as I understand it now expected behaviour in a one worker node deploy)
- The WEB UI "console" would not load, because of a router config issue
- Not a blocker just calling out you have to provision users, to give access to the WebUI. There is no default admin user
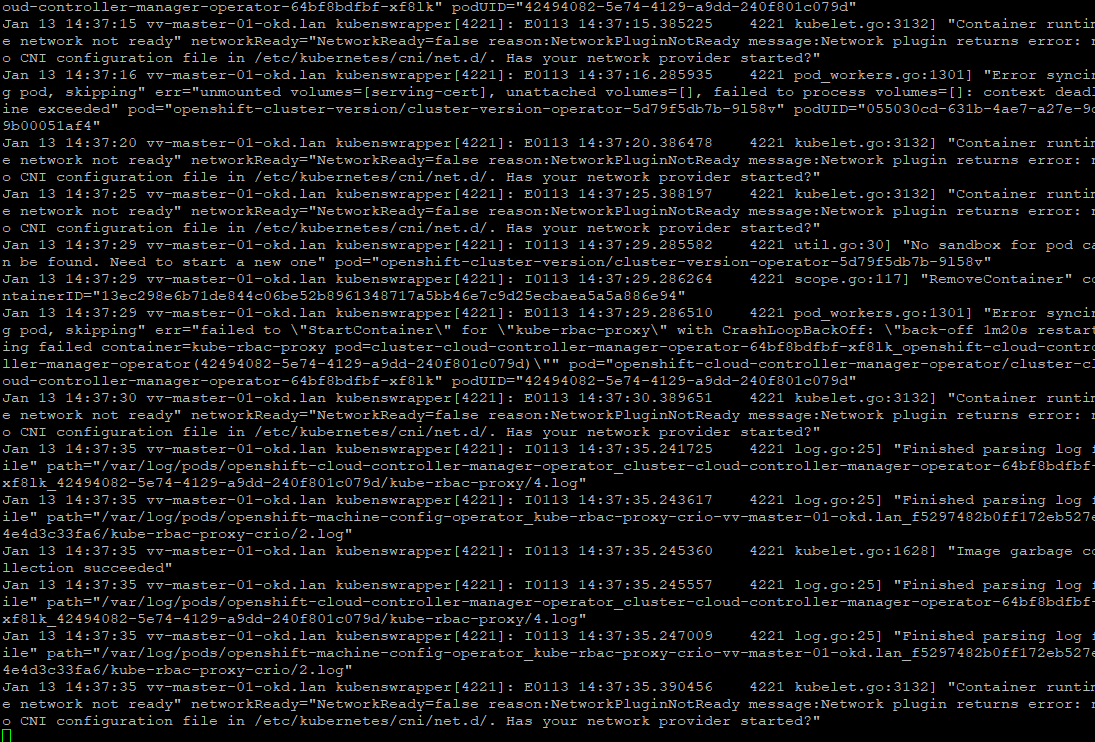
About the built-in openshift-install logging. There is no world in which I trust it with my time. Yes, I will run it, but I need to see and verify.
The only good thing I found about the installer logging is AFTER you flip HAProxy to the Master VM after successful bootstrap. It safely gives you a hard gate that tells you when the bootstrap can be powered off.
These are the installer logging commands below, and I will show you where I used them as a gate for when we power this all on.
./openshift-install wait-for bootstrap-complete --log-level=info
tail -f .openshift_install.logI am walking through the install again with you, show you signals at each step, and the commands that will show pass fail. I will also include the repeatable issues I resolved.
Here are my rough timings for this run. This could definitely be less going forward, but it is a decent indicator. These VMs are running on SSDs. I booted each service individually, and the end time reflects when that component turned green.
Bootstrap
-
9:15 Booted
-
9:21 journalctl -fu bootkube # Machine config good API ready
Master
-
9:28 booted master #two boots
-
9:32 master reboot
-
9:50 API Z ready
-
9:58 Bootstrap safe to remove
Worker
-
10:13 Boot worker #two boots
-
10:16 Worker Reboots
-
10:22 Approve CSR from OC
-
10:25 worker shows OC ready
-
10:35 Running UI
Powering Bootstrap:
##SSH using key
ssh-keygen -R 172.26.7.53
ssh -i ~/.ssh/okd_bootstrap_id_ed25519 [email protected]
sudo su -
#make sure doing things and not ton of errors
#ssh to bootstrap
#api ready/ok time to boot master
journalctl -fu bootkube # Should see action
crictl ps | grep kube-apiserver # If it makes you feel good
curl -k https://127.0.0.1:6443/readyz # This is the signal that you are good to boot master
curl -k https://127.0.0.1:6443/healthz # his is the signal that you are good to boot master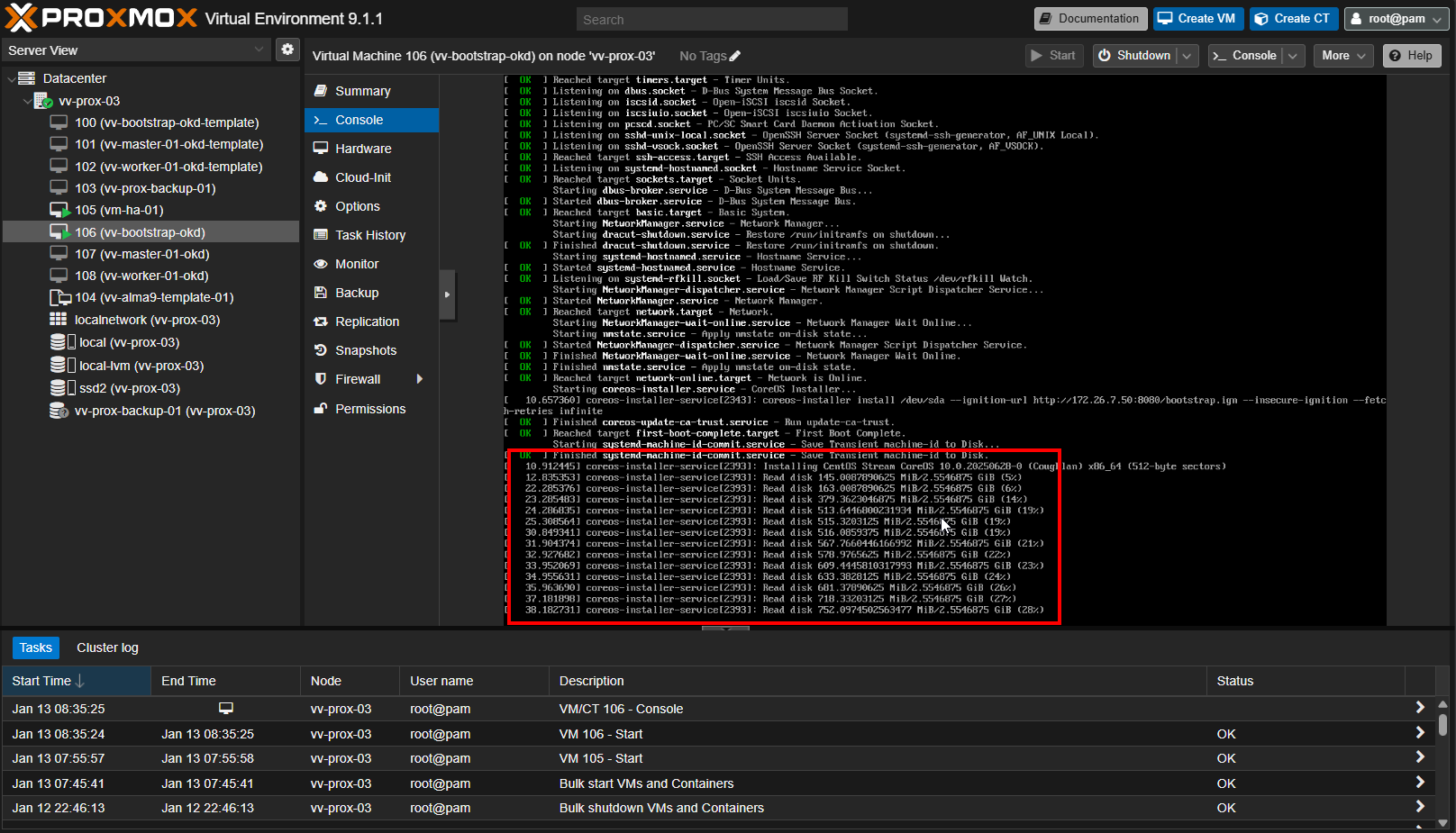

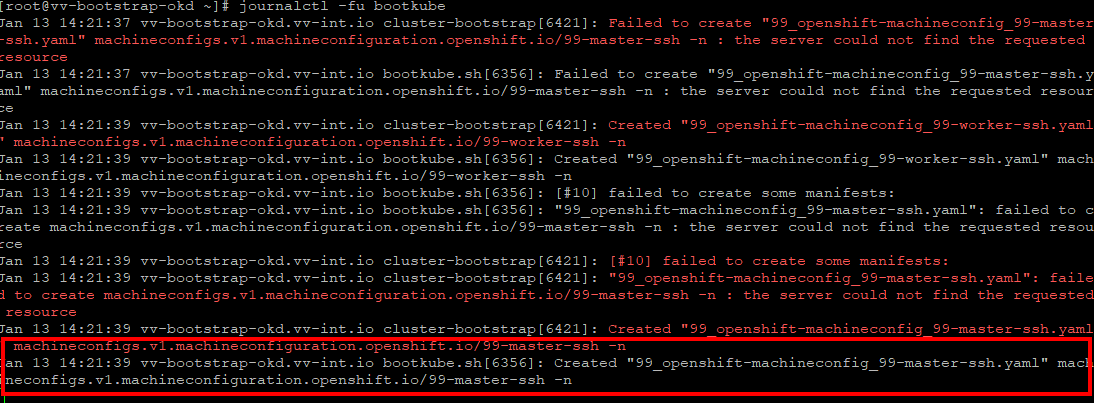
#On the bootstrap machine
curl -k https://127.0.0.1:6443/readyz # This is the signal that you are good to boot master
curl -k https://127.0.0.1:6443/healthz # his is the signal that you are good to boot master👍 Lets go power on that master
Powering Master
This is the step that eventually requires the HAProxy flip --> to the master backend. Only after config is ready and I will give you the gates for that This vm will boot get some config do somethings then reboot, its then you can ssh to it to get the info you seek.
##SSH using key
ssh-keygen -R 172.26.7.51
ssh -i ~/.ssh/okd_bootstrap_id_ed25519 [email protected]
sudo su -
## On installer VM
export KUBECONFIG=/root/okd/installer/auth/kubeconfig
oc get nodes
oc get csr
# ssh to master
systemctl is-active kubelet # Kubelet Is Healthy
journalctl -fu kubelet # follow the kube you will see ton of things that look like erropr but its just doing check and rechecks
journalctl -u kubelet --no-pager -n 2000 # Optional Deep Check
crictl ps | grep kube #Static Control Plane Pods Are Running
curl -k https://127.0.0.1:6443/readyz
curl -k https://127.0.0.1:6443/healthz
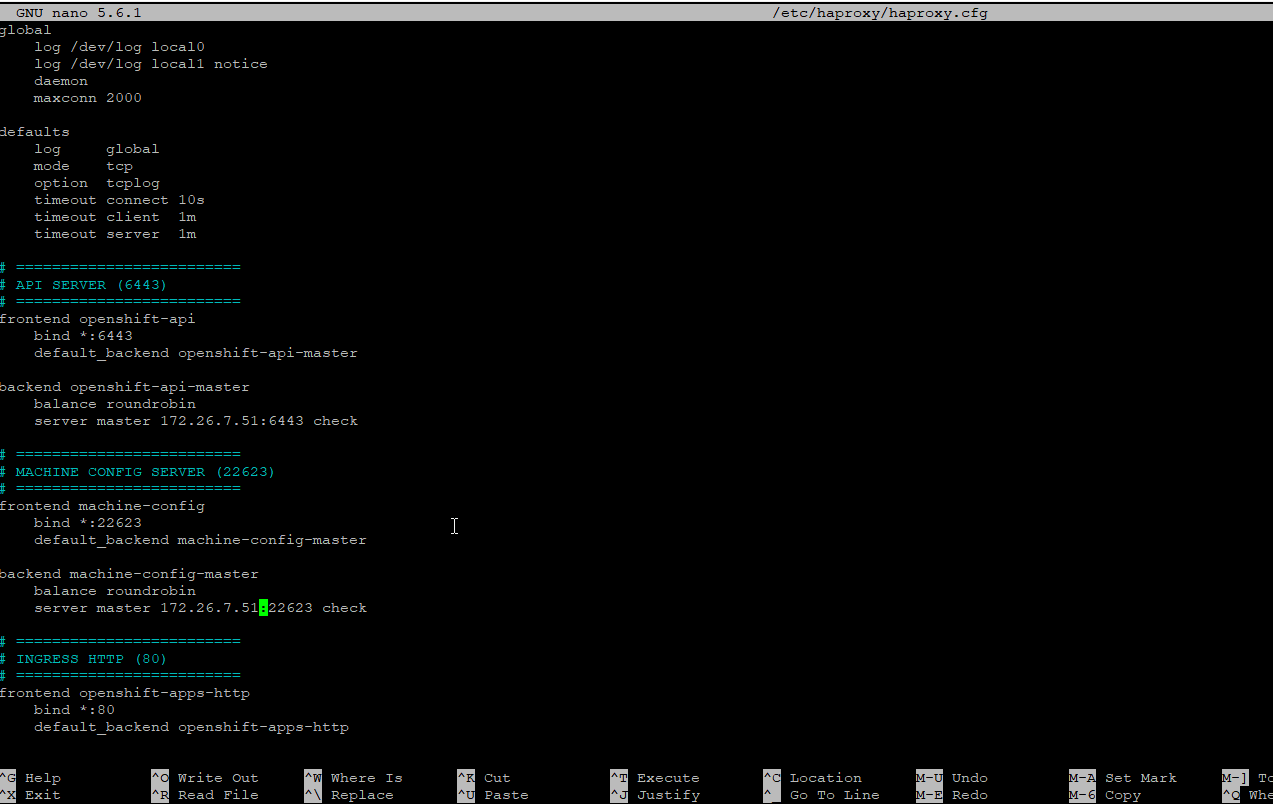
Once API is ready will be unavailable until you flip control plane in HA Proxy
nano /etc/haproxy/haproxy.cfg
haproxy -c -f /etc/haproxy/haproxy.cfg
systemctl reload haproxy
##Once HA Proxy is complete consult, it will tell you powerdown the boostrap VM
./openshift-install wait-for bootstrap-complete
#Everytime will see pending
oc get nodes
oc get csr
#approve all get it done
oc get csr -o name | xargs oc adm certificate approve
#ssh worker node look for bad things
journalctl -u kubelet -f
curl -k https://api.okd.vv-int.io:6443/readyz
curl -k https://api.okd.vv-int.io:6443/healthz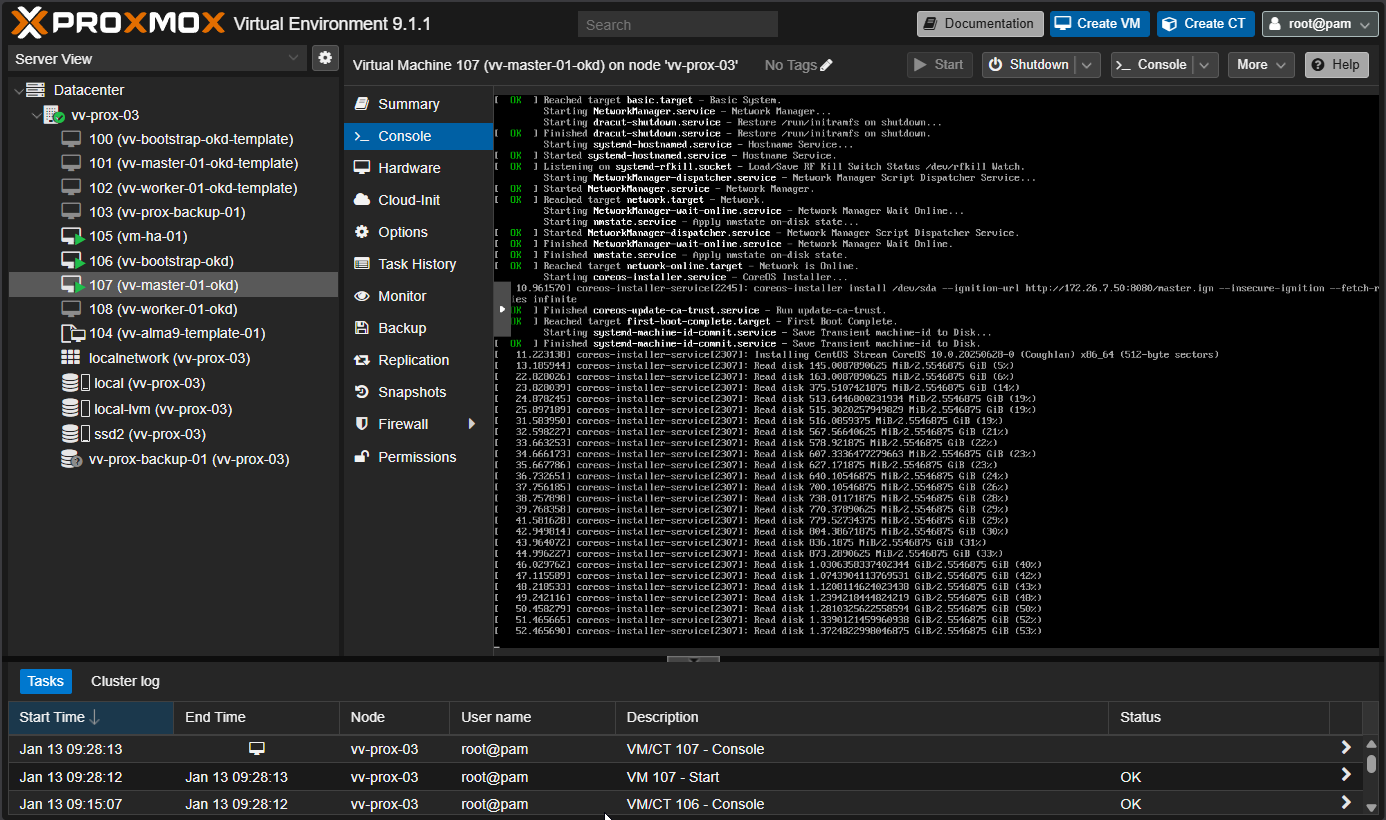
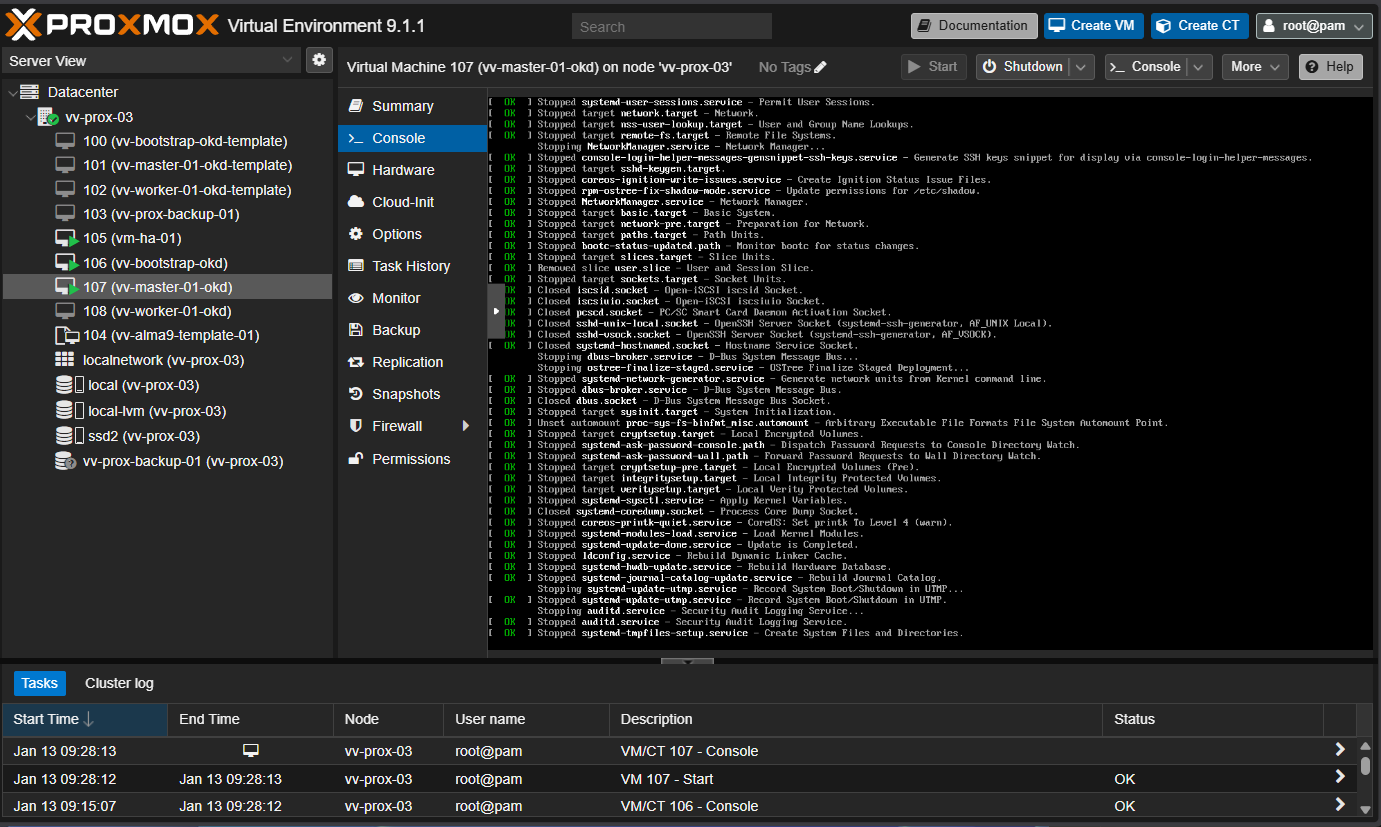
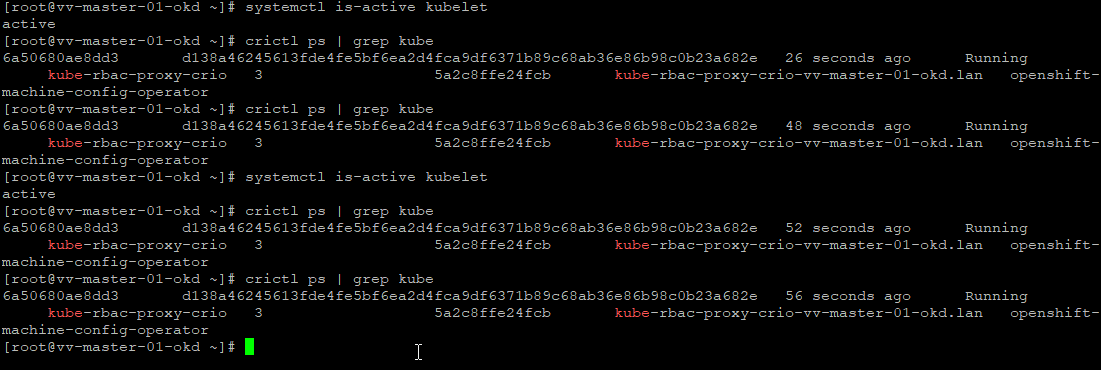

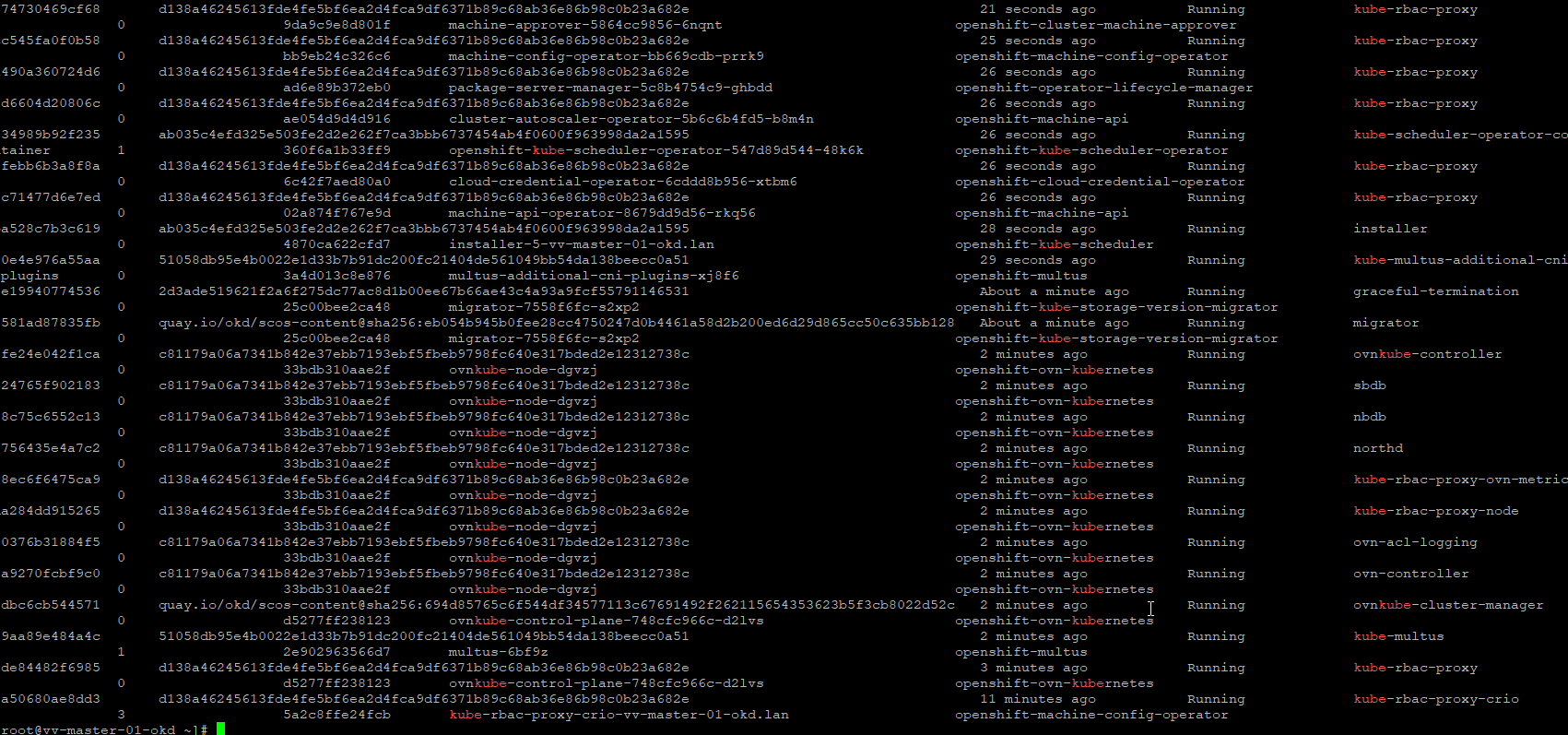



Time to power on the worker
##SSH using key
ssh-keygen -R 172.26.7.52
ssh -i ~/.ssh/okd_bootstrap_id_ed25519 [email protected]
sudo su -
#Everytime will see pending
oc get nodes
oc get csr
#approve all get it done
oc get csr -o name | xargs oc adm certificate approve
journalctl -u kubelet -f #ssh worker node look for bad things
#Ingress will always be scheduled on the master in a two node cluster
oc describe pod -n openshift-ingress -l ingresscontroller.operator.openshift.io/deployment-ingresscontroller=default
#Ingress patch and force router recreation
oc patch ingresscontroller default -n openshift-ingress-operator --type=merge \
-p '{"spec":{"nodePlacement":{"nodeSelector":{"matchLabels":{"node-role.kubernetes.io/worker":""}}}}' \
&& oc delete pod -n openshift-ingress -l ingresscontroller.operator.openshift.io/deployment-ingresscontroller=default
#Watch
oc get pods -n openshift-ingress -w -o wide
#Console Verify
oc get pods -n openshift-ingress -o wide
oc get deploy -n openshift-console
oc get pods -n openshift-console -o wide
oc get route console -n openshift-console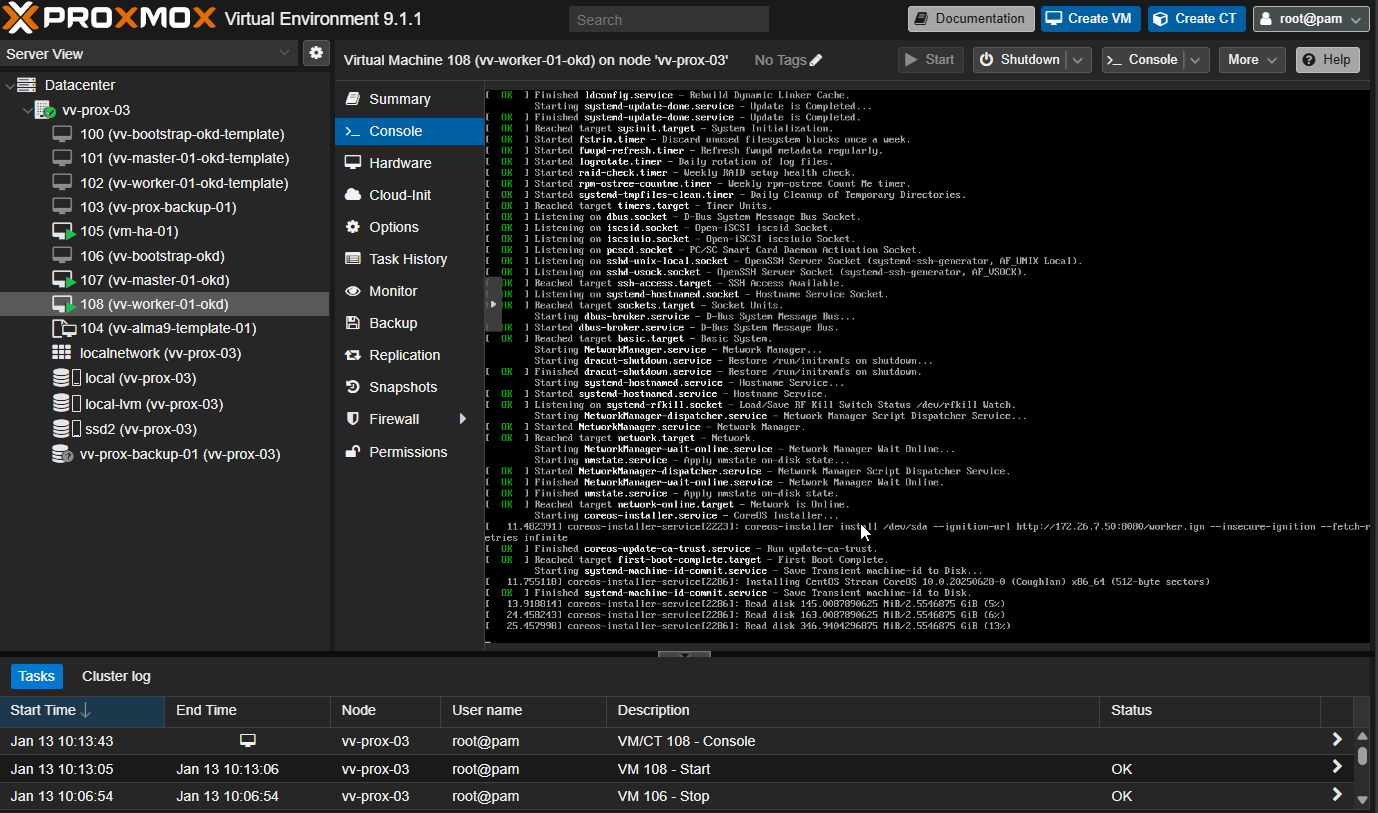

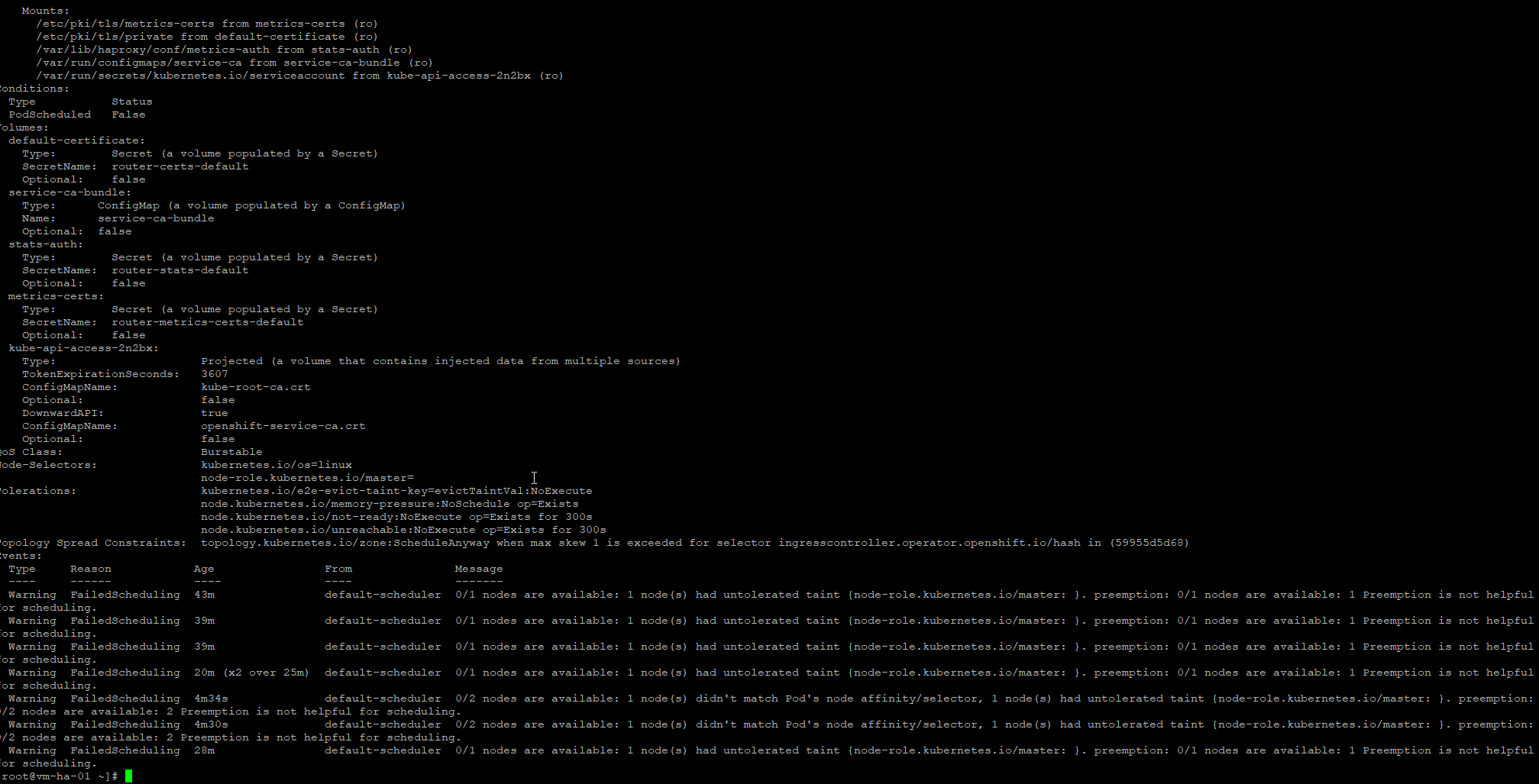

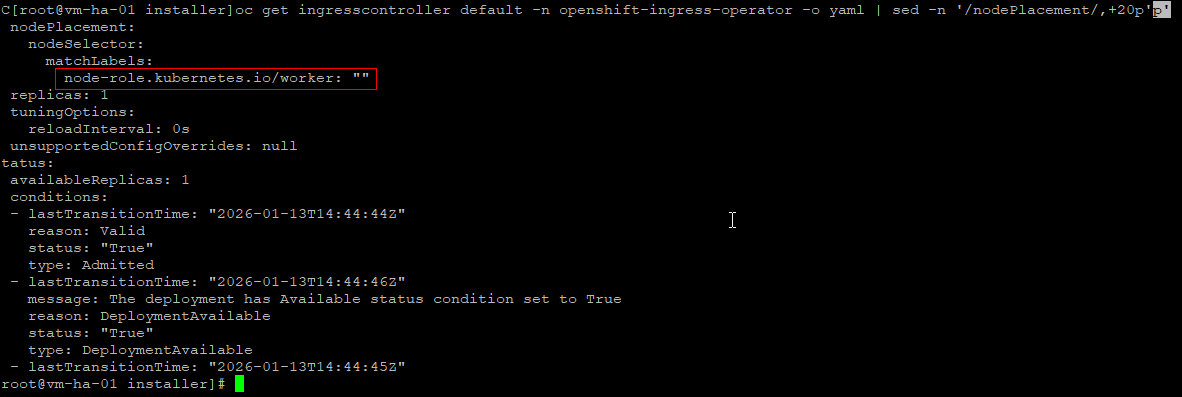
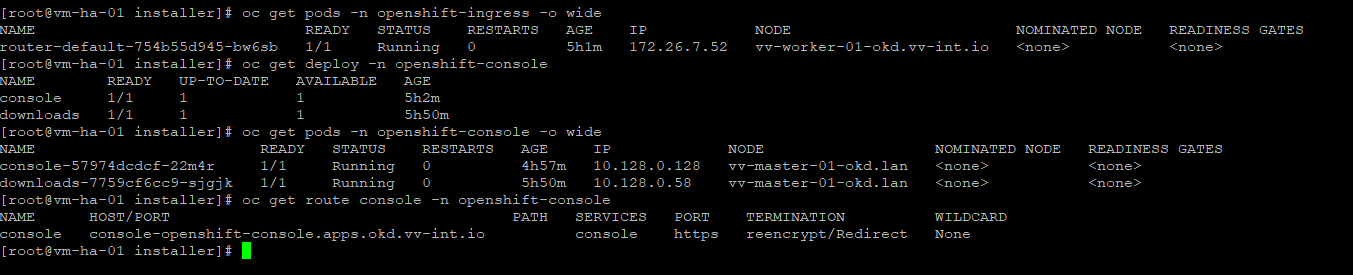
To help you understand why we had to patch the router during the deploy: as I understand it today, in a 1-master / 1-worker OKD cluster the router gets created before the worker is ready and it still expects HA, where no HA can exist.
It then remains Pending because:
-
the master is tainted (so nothing schedules there by default), and
-
the only worker is not yet fully Ready and schedulable.
Once the single worker becomes fully Ready, the router can finally schedule. It might have eventually rescheduled on its own, but I have not verified that. The HA router requirement makes me think no, which is why the patch was necessary.
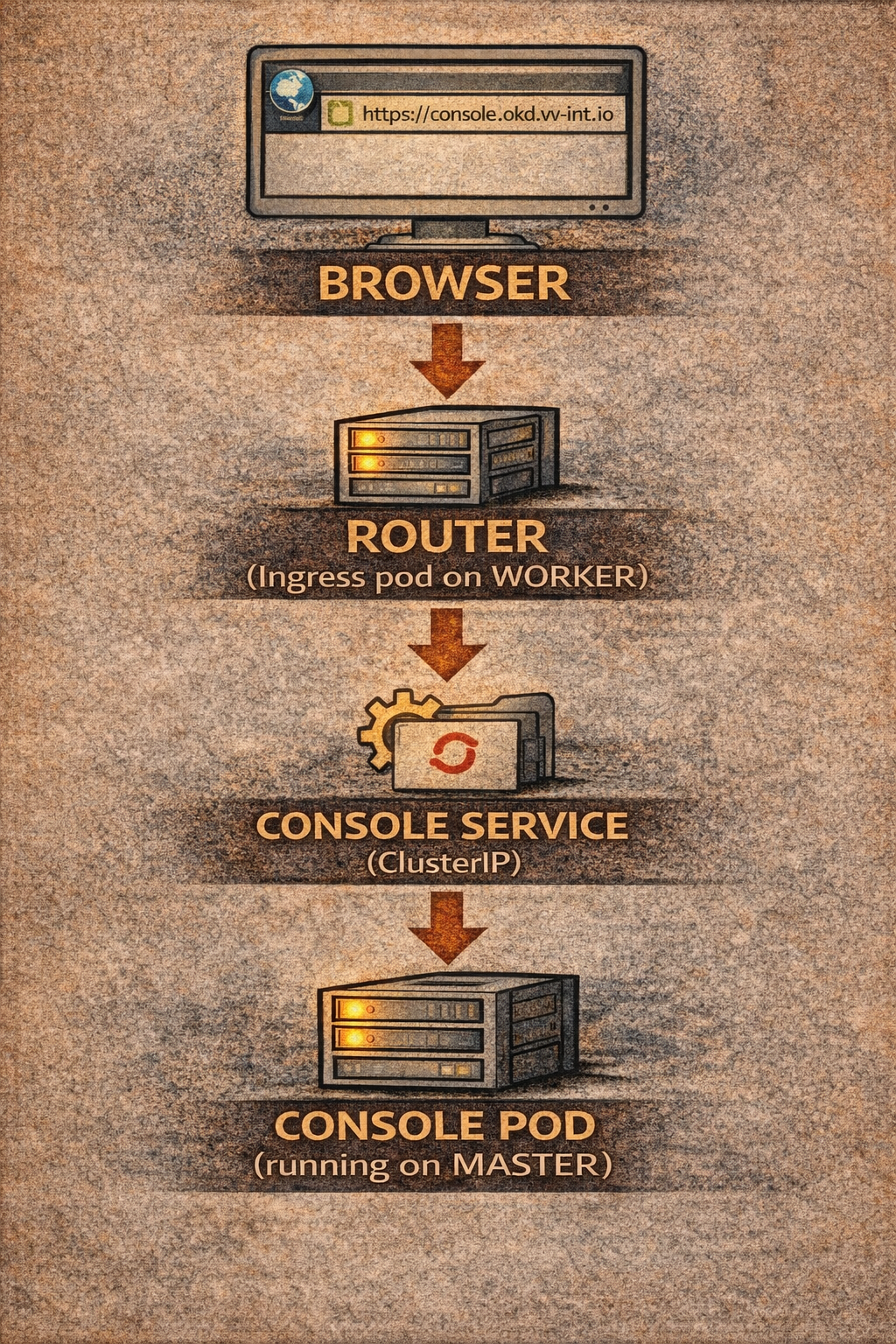
Time to fix auth, in the installer directory
#Create the file
htpasswd -c -B -b users.htpasswd admin 'strongpw'
# Create or update the htpasswd auth secret (safe to re-run)
oc create secret generic htpasswd-secret \
--from-file=htpasswd=users.htpasswd \
-n openshift-config
# Configure cluster OAuth to use local HTPasswd identity provider
oc apply -f - <<EOF
apiVersion: config.openshift.io/v1
kind: OAuth
metadata:
name: cluster
spec:
identityProviders:
- name: local
mappingMethod: claim
type: HTPasswd
htpasswd:
fileData:
name: htpasswd-secret
EOF
# Grant cluster-admin role to user "admin"
oc adm policy add-cluster-role-to-user cluster-admin admin # add adminI have observed that this seems to take 10-30 Seconds, and once you referesh the UI you will see
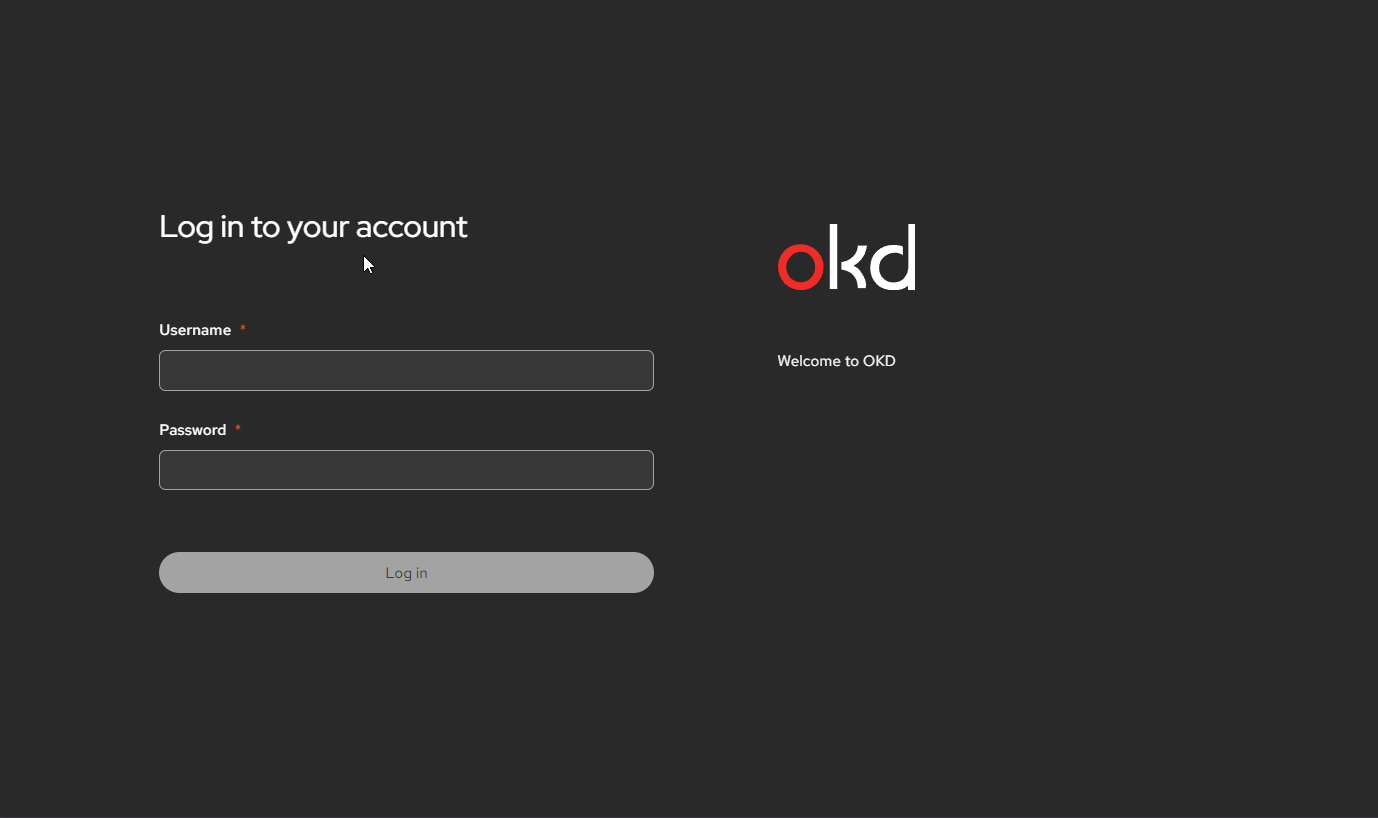

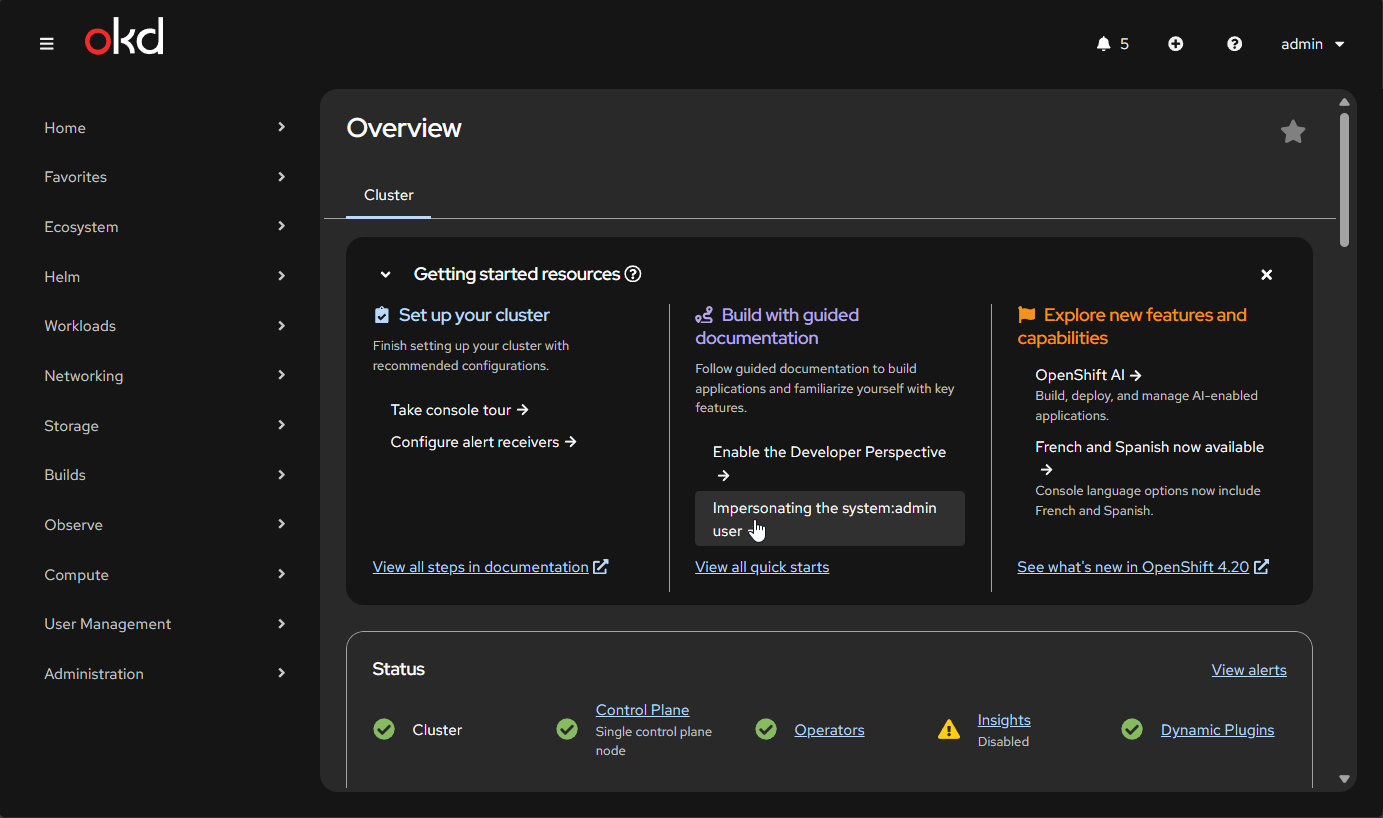
Boom
So yeah, I have done simpler implementations, but I feel confident I could deploy this anywhere at this point and can't wait to do some follow up posts about OKD OpenShift. I have a ton of things I want to check out , networking, storage, actual ingress. I think its really cool that VM's are a first class citizens. It means existing automation frameworks are just bolt on, and that is just cool. The fact you can do bare metal, public cloud just means you have to buy-in once.
I will probably deploy another worker node, which reminds me to remind both you and me. Back up that install-config.yaml and regenerate the ignition files before you decide to add a worker. Reusing old worker ignitions invites anarchy.🚀🚀🚀
Another non-negiotiable, especially in a prod deployment, would be to backup the entire installer directory as you will need the SSH private keys and /auth/kubeadmin install-config.yaml
- Moving admin to another VM
- Creating additional workers
I would everything on this deploy to work exactly the same in an VMware, bare metal etc.
I hope this post was informative , I feel if you follow it and test properly along the way you will end up with a functional OpenShift cluster.
Thanks for reading ! -Christian
<script type="application/ld+json">{ "@context": "https://schema.org", "@type": "Article", "headline": "Four Days, from Zero to One: My Descent Into Madness with OKD on Proxmox", "description": "A real-world account of deploying OKD on Proxmox from zero, detailing networking challenges, installer behavior, and lessons learned over four days.", "author": { "@type": "Person", "name": "Christian" }, "publisher": { "@type": "Organization", "name": "Virtual Velocity", "url": "https://virtualvelocity.io", "logo": { "@type": "ImageObject", "url": "https://virtualvelocity.io/user/images/logo.png" } }, "datePublished": "2026-01-07", "dateModified": "2026-01-07", "mainEntityOfPage": { "@type": "WebPage", "@id": "https://virtualvelocity.io/tech-blog/my-descent-into-madness-okd-red-hat-open-shift-upstream-4-days-from-0-to-1" }, "keywords": [ "OKD", "OpenShift", "Proxmox", "Kubernetes", "HAProxy", "DNS", "DHCP", "CentOS Stream", "OKD installation" ] }

